
Motivation and Architectural Relevance
Pretraining large language models (LLMs) requires massive computational resources, and the MLPerf™ Training benchmark suite has reflected that reality. Pretraining tests like Llama 3.1 405B and Llama 3.1 8B focus on dense models that can require substantial multi-node infrastructure. This can create a barrier to entry for many organizations looking to participate in benchmarking.
To address this, the MLPerf Training Working Group—led by a task force from AMD, NVIDIA, and NIT University—is introducing a new pretraining benchmark: GPT-OSS 20B. A modern, Mixture-of-Experts (MoE) alternative, GPT-OSS 20B allows researchers and organizations to evaluate the complex routing logic and sparse computation patterns common to MoE architectures—on hardware configurations as small as a single 8-GPU node.
Model Selection and Architecture
The task force identified GPT-OSS 20B as the ideal small-scale candidate with a modern, sparse architecture for three reasons:
- Sparse Efficiency: The model features 21B total parameters, but utilizes an MoE design that activates only 3.6B parameters per token. This allows it to maintain a massive knowledge base with a computational footprint similar to less dense models.
- From-Scratch Training: To keep the benchmark simple and avoid the overhead of multi-gigabyte checkpoint downloads, GPT-OSS 20B is trained from randomized weights. This makes it a pure test of a system’s ability to optimize a sparse model from its initial state.
- Reference Implementation: The reference code is built on AMD’s Primus framework, a versatile new training library supporting both AMD and NVIDIA backends. Primary validation was conducted on AMD Instinct™ MI355X and NVIDIA B200 systems.
Dataset and Tokenization
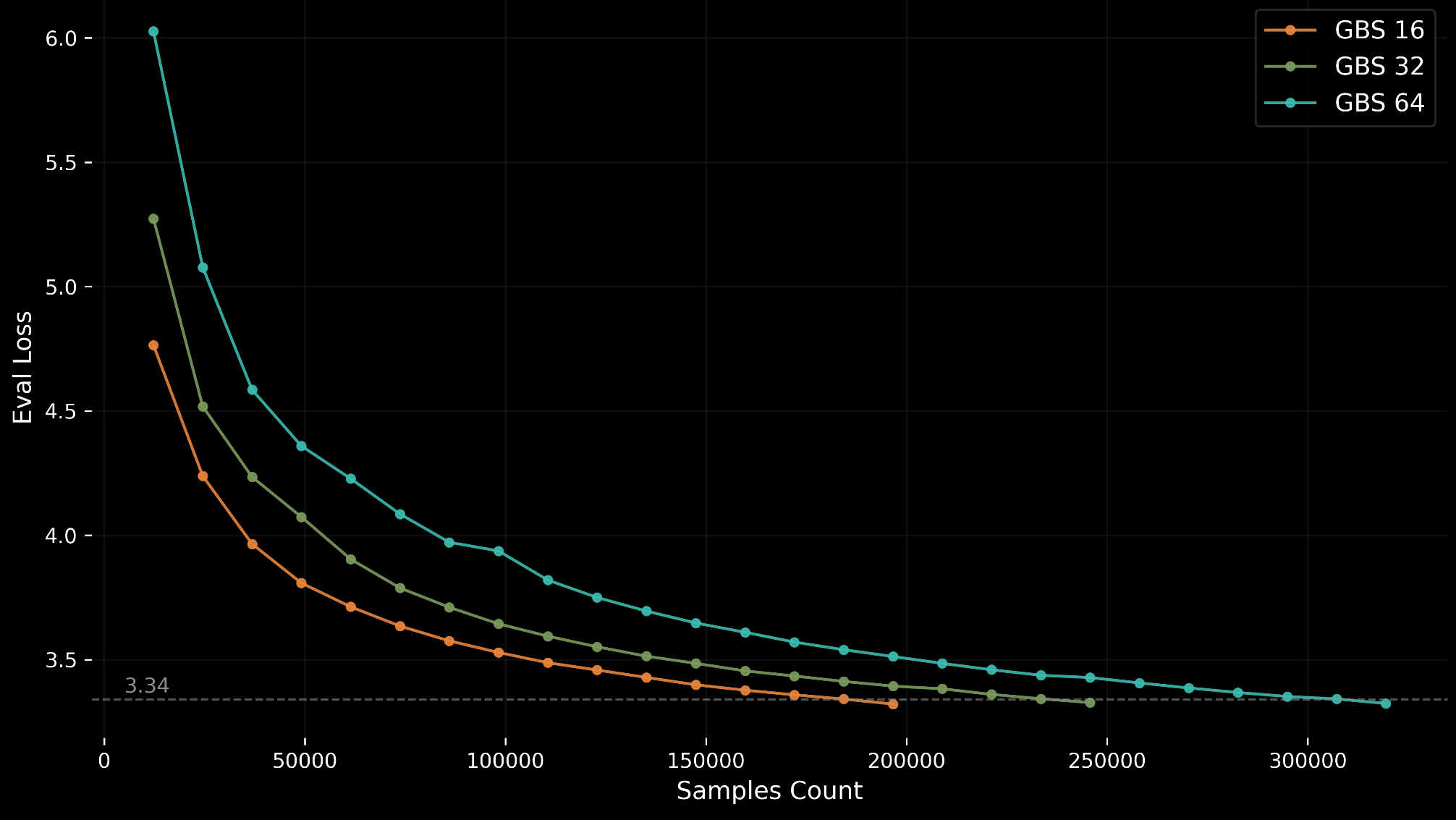
GPT-OSS 20B leverages the C4 (Colossal Cleaned Common Crawl) dataset, specifically using the same pre-tokenized subset and Llama-3 compatible tokenizer as the Llama 3.1 8B benchmark. This makes it easy for submitters who already have the dataset setup for other MLPerf Training benchmarks to run GPT-OSS 20B as well. The training data consists of approximately 80 GB of pre-shuffled C4 shards hosted on MLCommons™ storage. To maintain stability, the benchmark evaluates against the first 1,024 samples of the validation set every 12,288 samples (768 iterations at GBS=16).
The Challenge of Statistical Variance (CV)
A primary objective in benchmarking is ensuring fairness. In large-scale training, this is measured by the Coefficient of Variation (CV), or the ratio of the standard deviation to the mean ($CV = \frac{\sigma}{\mu} \times 100\%$).
Why High CV Undermines Fairness
When a benchmark has a high CV, it suffers from “statistical noise.” If one run takes 170k samples and another takes 250k samples due to random chance, the results no longer reflect hardware or software superiority. For a benchmark to be a trusted industry standard, a user must be able to reproduce the results. High variance makes it impossible to distinguish between an engineering breakthrough and luck.
Engineering Stability: The Path to 5% CV
One common approach to reducing CV is starting from a pretrained checkpoint that has already passed through the unstable early stages of training. The task force wanted to keep the benchmark simple, so requiring submitters to download a multi-gigabyte checkpoint would add overhead and complexity. Instead, the task force implemented three critical technical interventions to reduce CV from approximately 15% to less than 5%.
1. Eliminating Validation Noise
Early tests showed massive, non-representative spikes in evaluation loss.
- The Discovery: The validation dataset was being shuffled at every evaluation interval. In a sparse MoE model, where routing is highly sensitive to input distribution, this shuffling introduced artificial “jitter.”
- The Fix: The benchmark now mandates evaluation on a static, unshuffled set of the first 1024 samples of the C4 validation set. This ensures the test remains identical across every step of every run.
2. Stabilizing the Optimizer
While many modern models use an Adam epsilon ($\epsilon$) of $10^{-8}$, the task force found this caused excessive divergence in 20B-scale MoE training from scratch. By aligning to $\epsilon = 10^{-5}$ (the standard used in Llama 3.1 8B), the team provided the numerical stability necessary to prevent “unlucky” gradient updates from derailing the sparse experts.
3. Standardizing Initialization
Technical Configuration and Quality Metrics
To ensure all participants start with the same “statistical energy,” the task force strictly defined the weight initialization standard (init_method_std = 0.008). This prevents variance born from different starting points in the high-dimensional loss landscape.
The target accuracy for the benchmark is a validation loss (log perplexity) of 3.34. This target was chosen based on extensive sweeps on AMD MI355X and NVIDIA B200 hardware, representing a point of stable convergence that balances thoroughness with a reasonable runtime (~6.5 hours to convergence) using BFloat16 precision.
| Feature | Specification |
| Model Type | Mixture-of-Experts (MoE) |
| Active Parameters | 3.6B per token |
| Sequence Length | 8,192 |
| Expert Parallelism | 8 |
| Target Loss | 3.34 |
| Submission Requirement | 10 runs per configuration (to average out noise) |
To optimize for their specific hardware, submitters are permitted to tune three hyperparameters: global batch size, learning rate, and learning rate warmup.
Conclusion
GPT-OSS 20B brings MoE pretraining into the MLPerf Training benchmark suite. By identifying and neutralizing the sources of training variance—specifically validation shuffling, optimizer instability, and initialization inconsistency—the task force has delivered a stable, high-fidelity benchmark that remains accessible to all submitters. This ensures that MLPerf Training v6.0 scores reflect genuine hardware and software efficiency.
GPT-OSS 20B provides the community with a standardized way to evaluate sparse pretraining performance alongside the suite’s existing dense workloads. The reference implementation is available on the MLCommons GitHub repository.
For additional information on MLCommons and details on becoming a member, please visit MLCommons.org or email [email protected].