
When MLCommons announced the Chakra working group in July 2023, the premise was simple but ambitious: AI systems are moving too fast for the traditional benchmarking and co-design playbook. Production workloads live behind walls of proprietary code and models. Simulators, emulators, and replay tools each invent their own representations. And the workloads driving the next generation of AI supercomputers — frontier-scale LLM training, sparse Mixture-of-Experts (MoE) models, disaggregated inference — change at a pace that the industry has never seen before.
On May 21, 2026, at the MLSys 2026 Industry Track, the Chakra working group presented a comprehensive paper on what that vision has grown into: an open, interoperable ecosystem for performance benchmarking and software/hardware co-design across the AI stack. The paper, MLCommons Chakra: Advancing Performance Benchmarking and Co-design using Standardized Execution Traces, is a milestone for an effort co-chaired by Srinivas Sridharan (NVIDIA) and Tushar Krishna (Georgia Institute of Technology), with active contributions from industry and academia, including but not limited to NVIDIA, AMD, Meta, Keysight, HPE, Scala Computing, Georgia Institute of Technology, and Harvard University.
The paper is available here: MLCommons Chakra MLSys 2026 Paper (arXiv)
The problem: a fragmented co-design loop
Designing modern AI platforms, with clusters of thousands of NPUs (NVIDIA Hopper/Blackwell, AMD Instinct, Google TPU, and others) connected by high-speed scale-up and scale-out fabrics, is an iterative loop. Teams observe workloads in production, reproduce them via representative benchmarks, design and evaluate next-generation systems with simulators and emulators, validate the silicon, and finally deploy at scale. Then the cycle starts again.
The Chakra paper argues that the tools driving this loop are deeply fragmented. Hyperscalers and cloud service providers can’t easily share proprietary models. Simulators and emulators from compute, network, and switch vendors each speak their own dialect. Open benchmarks like MLPerf evolve on release cycles that lag the pace of AI innovation. The result is siloed optimization, longer time-to-market for new platforms, and limited ability for academics and startups to participate in production-relevant co-design.
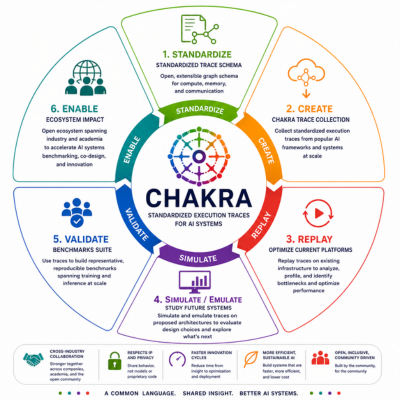
The Chakra Answer: An Open Execution Trace Ecosystem
At the center of Chakra is the Execution Trace (ET)—a portable, graph-based representation of distributed AI workload behavior.
Rather than exposing model weights, datasets, or proprietary source code, Chakra traces capture the performance-relevant behavior of workloads: compute operations, communication patterns, memory activity, dependencies, timing information, and parallelization strategies.
The idea is deceptively simple but powerful:
A software organization can share an execution trace with a hardware vendor. The hardware vendor can drive internal simulators, emulators, or replay frameworks using that trace. Insights flow back to improve performance, without requiring either side to exchange proprietary IP.
In many ways, Chakra serves as a common language for AI infrastructure benchmarking and co-design, enabling more agile collaboration across workloads, software stacks, silicon, networking, and systems research.
Enabling the Full AI Infrastructure Lifecycle
One of Chakra’s defining strengths is its ability to support the entire AI systems co-design lifecycle through its common execution trace abstraction. Chakra traces can be collected directly from modern AI frameworks such as PyTorch, NVIDIA NeMo, and vLLM, enabling faithful representations of real training and inference workloads. These traces can then be replayed on existing platforms for debugging, performance analysis, and bottleneck identification without requiring access to proprietary models or datasets; simulated or emulated to study future architectures, interconnects, and deployment strategies using realistic workload behavior rather than synthetic approximations; and used for hardware-in-the-loop (“shift-left”) validation, helping organizations uncover system bottlenecks and subtle interactions earlier in the development cycle before large-scale deployment.
From Working Group to Ecosystem
“What began as an idea to make AI workload behavior more portable and reproducible has grown into a vibrant community effort spanning hyperscalers, silicon vendors, infrastructure providers, tool developers, and researchers. Seeing the community rally around shared tooling and interoperable methodologies has been incredibly energizing. This milestone reflects a shared commitment to making AI infrastructure innovation more collaborative and accessible to the broader community.”
— Srinivas Sridharan and Tushar Krishna, Co-Chairs, MLCommons Chakra Working Group
Today, the Chakra Working Group spans a 40+ member collaboration across hyperscalers, full-stack AI vendors, silicon providers, networking companies, system integrators, simulation and emulation tool suppliers, startups, and academia.
The ecosystem has expanded significantly since its launch:
- Native support in PyTorch and NVIDIA NeMo, with trace collection now officially supported in both frameworks
- Integration into vLLM, enabling modern inference and serving trace collection
- Native support in ASTRA-sim, the open-source distributed AI simulator widely used for AI system design-space exploration
- Commercial adoption in tools such as Keysight AI Data Center Builder and Scala Computing platforms
- Support within proprietary internal simulation environments, including AMD workflows and Meta, NVIDIA trace replay infrastructures

Part of the Chakra Team at MLSys 2026. From Left: Jinsun Yoo (GT), Winston Liu (Keysight), Hanjiang Wu (GT), Huan Xu (GT), David Kanter (MLC), Tushar Krishna (GT), Vinay Ramakrishnaiah (AMD), Spandan More (AMD), Brad Beckmann (AMD), Brian Coutinho (NVIDIA), Vijay Janapa Reddi (Harvard)

Chakra Presentation at MLSys 2026 by Brian Coutinho (NVIDIA)
Open Trace Library for the Community
The core goal of Chakra is to make AI systems benchmarking and co-design more reproducible and accessible to the broader community.
To support this vision, the Chakra Working Group is also releasing an Open Trace Library for the Community—a growing collection of representative execution traces from real AI workloads spanning diverse models, parallelization strategies, and deployment scenarios.
The initial trace releases were collected with support from Georgia Tech’s AI Makerspace and Hewlett Packard Enterprise (HPE), leveraging production-scale GPU infrastructure to capture representative workloads across GPT-3, Llama, Mixtral, DeepSeek-MoE, and other distributed AI systems. These traces enable researchers, startups, and infrastructure teams to benchmark systems, reproduce workload behavior, and evaluate future AI platform designs—without requiring access to proprietary production environments.
Explore the Open Trace Library here: Chakra Trace Library
Access the Chakra codebase here: MLCommons Chakra Repository
Voices from the ecosystem
“Chakra is an indispensable framework that enables to debug AI systems and optimize performance. Standardization of execution traces enables cross-workload optimizations and debug at datacenter scale. Real-time traces along with open analysis tools helps to understand behavior and execution bottlenecks of highly-parallel distributed workload. This technology can be applied at design phase of integrated datacenter-scale computer. We’re proud to support the MLCommons Chakra effort and the collaboration behind this work” – Michael Kagan, CTO, NVIDIA
“Optimizing AI benchmarks and workloads across AMD Instinct and ROCm — from inference serving to fine-tuning and pre-training — means navigating a system design space where robust methodology and simulation-driven exploration accelerate time-to-performance. Chakra’s graph-based execution traces capture real AI workload behavior in a portable, vendor-neutral schema, giving the industry a common language for benchmarking and co-design and giving AMD a faithful representation of MLPerf-class workloads to drive internal simulation on AMD Instinct silicon. That interoperability turns architectural advantage into reproducible performance.” — Meena Arunachalam, Fellow and Director, AI Performance Engineering, AMD, Board Member MLCommons
“I had the privilege of being associated with Chakra since its inception. My former teammates at Meta started Chakra to enable platform agnostic way collecting production workload traces. It greatly enhanced the capabilities of engineering teams at Meta to instrument and analyze potential performance issues at scale. In my current role at AMD I get to notice how Chakra is enabling performance analysis of our products and driving crucial roadmap decisions.” – Shashidhar Gandham, Former Director of Networking at Meta, now Corporate VP, AMD
“Chakra has become a foundational component of our AI systems research at HPE, enabling high-fidelity performance emulation and large-scale design exploration for next-generation AI infrastructure. Our teams have leveraged Chakra to study training, parallelization, and resilience strategies for extreme scale AI models well before access to hyperscale GPU deployments. Its presentation at MLSys 2026 underscores the growing importance of open, standardized trace ecosystems in accelerating innovation across the AI systems community.” – Puneet Sharma, Fellow and VP, HPE
“One of the persistent challenges in AI infrastructure development is that system-level behaviors, particularly interactions between collective communication, memory pressure, and congestion control, often surface after clusters are deployed, when the cost of correction is higher. Shift-left validation addresses this, but only if workloads driving that validation are realistic. Chakra’s execution trace format gives the entire ecosystem a portable, workload-faithful representation that can be shared across organizational boundaries without exposing proprietary models or source code. Keysight has invested in this effort because we believe open, interoperable foundations like Chakra are essential for helping the industry close the feedback loop faster rather than operating in isolated silos.” Ram Periakaruppan, Vice President and GM, Network Applications & Security business at Keysight. More perspective from Keysight here.
“Chakra is a fantastic showcase of the role Georgia Tech plays in connecting academic research with real-world systems. We can bring together expertise spanning the full AI stack in really the only way that makes complex work like this possible” Arijit Raychowdhury, Steve W. Chaddick School Chair of ECE, Georgia Institute of Technology. More perspective from Georgia Tech here.
“Open benchmarks and open tooling have historically played a foundational role in accelerating progress in computing because they give researchers and practitioners a common way to evaluate ideas, reproduce results, and build on one another’s work. Chakra extends that philosophy to modern AI infrastructure by creating a shared representation of workload behavior, helping bridge insights from academia and industry while democratizing access to realistic AI systems research and enabling deeper collaboration across the ecosystem.” — Vijay Janapa Reddi, Harvard University; Board Member, MLCommons
“MLCommons builds shared standards that move the entire ecosystem forward like MLPerf. Chakra brings that philosophy to AI systems co-design, giving researchers and companies a common framework for understanding and reproducing workload behavior across hardware, software, and infrastructure boundaries.” – David Kanter, Co-Founder and Head of MLPerf, MLCommons
Looking Ahead
The Chakra ecosystem continues to evolve.
Future efforts include support for larger and more efficient trace representations for frontier-scale models, tighter integration with benchmarking efforts such as MLPerf Storage, and emerging work on InfraGraph, a portable infrastructure description framework designed to complement Chakra’s workload traces with graph-based descriptions of compute, memory, and network topologies.
AI infrastructure is advancing at extraordinary speed, and no single organization can solve the systems challenges ahead alone.
Chakra represents an important step toward a more collaborative AI systems ecosystem—one where workloads, tools, and methodologies become easier to share, reproduce, benchmark, and optimize across the stack.
To get involved, contribute traces or tooling, or join the working group, visit the MLCommons Chakra community pages: MLCommons Chakra Working Group
—–
Chakra means “wheel” in Sanskrit — a fitting name for an ecosystem built around the cyclic, iterative nature of AI systems co-design.