
Motivation and Architectural Relevance
As Large Language Model (LLM) development increasingly adopts sparse computation, the benchmarks used to evaluate training performance need to keep pace. MLPerf™ Training v6.0 adds a large-scale pretraining benchmark built on DeepSeek-V3, a Mixture-of-Experts (MoE) architecture with 671B total parameters, of which 37B are activated per token.
This benchmark captures the performance of critical innovations now standard in the industry, including Multi-head Latent Attention (MLA) and auxiliary-loss–free load balancing.
Technical Architecture & Implementation
DeepSeek-V3 introduces specific computational patterns that differentiate it from the dense models (e.g., Llama 3.1) currently in the suite:
- Multi-head Latent Attention (MLA): Unlike standard Multi-Head Attention (MHA), MLA uses low-rank joint compression for Key-Value (KV) caches to reduce memory bandwidth bottlenecks during training and inference.
- Fine-Grained Expert Segmentation: Each expert feed-forward network (FFN) is segmented into $m$ smaller experts. While a typical MoE might use a top-2 routing over 16 experts, DeepSeek-V3 expands this to 160 routed experts plus shared experts to capture common knowledge.
- Multi-Token Prediction (MTP): The model is trained with a 2-token prediction objective. This requires a shared trunk and two dedicated output heads, increasing the compute-to-memory ratio during the backward pass.
- Auxiliary-Loss-Free Load Balancing: To prevent routing collapse without the performance degradation of heavy auxiliary losses, a bias term is dynamically adjusted for each expert based on real-time load.
Benchmark Definition & Reference Setup
The task is defined as LLM Pretraining using a Mixture-of-Experts objective.
Dataset and Tokenization
- Dataset: C4 (Colossal Clean Crawled Corpus)
- Tokenizer: Llama-3 compatible tokenizer (128k vocabulary)
- Sequence Length: 4,096 tokens
Convergence and Checkpointing
The task force identified that MoE models spend early training time in a state of token imbalance. Since the benchmark captures only a small slice of the full end-to-end training, this token imbalance state lasted for approximately 50% of the benchmarking time, which is not representative of steady-state MoE training. To ensure the benchmark measures steady-state hardware efficiency, the task force adopted a warm-start approach.
Since the benchmark uses a Llama 8B tokenizer instead of the original DeepSeek tokenizer, initializing from a Hugging Face checkpoint leads to significant token imbalance. To address this, the task force fine-tuned the checkpoint for 50 steps, bringing the token-per-expert distribution close to that obtained with the original DeepSeek tokenizer (Fig 1). The resulting checkpoint is in HuggingFace format and is hosted by MLCommons. This methodology ensures more than 98% of the benchmark run occurs in a balanced expert state, reflecting long-term training dynamics.

(Fig 1)
Global Batch Size (GBS) Selection
This benchmark requires a GBS of 15,360 or greater.While internal testing showed that the model maintains computational efficiency at lower batch sizes (e.g., 512, 1k, or 2k), the task force mandated a higher floor for three reasons:
- Representativeness: The original DeepSeek-V3 pretraining used a batch size scheduling strategy that peaked at 15,360. To remain representative of the real-world, large-scale pretraining described in the paper, the benchmark targets the 15k-18k range.
- Fairness in Benchmarking: Setting a minimum GBS of 15k ensures a fair and representative playing field for all submitters, preventing “hero runs” on tiny batch sizes that don’t reflect production-scale MoE training.
- Convergence Scaling: The task force established a square-root scaling rule for the learning rate to maintain stability across these larger batch sizes:
Engineering Challenges and Validations
Development of the reference implementation (using NVIDIA NeMo Megatron-bridge) highlighted several critical requirements for convergence:
- Expert Parallelism (EP): For a single layer, routed experts are uniformly deployed across 64 GPUs (8 nodes). Node-limited routing is enforced where each token is sent to a maximum of M=4 nodes.
- Memory Management: Expert capacity must not be restricted to avoid out-of-memory errors (OOMs) caused by token imbalance during the initial steps after checkpoint loading, ensuring the benchmark remains representative of real-world training conditions.
- Target Metric: The benchmark targets a cross-entropy validation loss of 3.6 with a Coefficient of Variation (CV) of 1.5% (Fig 2).
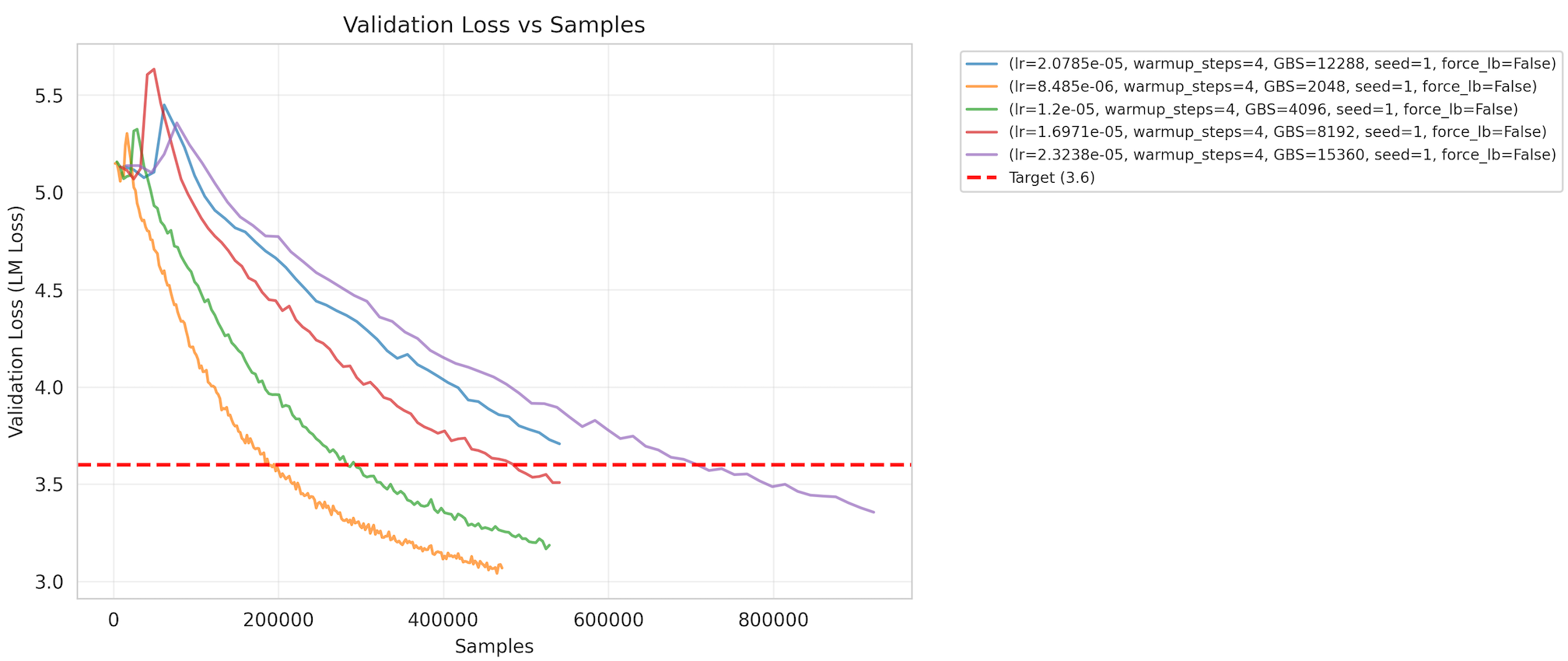
(Fig 2)
Conclusion
This benchmark provides a standardized platform for evaluating the training efficiency of a leading open-weights MoE model at production scale. By defining clear requirements for convergence, batch size, and expert parallelism, the DeepSeek-V3 benchmark ensures that MLPerf Training continues to reflect the contemporary state of AI infrastructure.
The reference implementation is available on the MLCommons GitHub repository, and the task force welcomes submissions and feedback from the community. For additional information on MLCommons and details on becoming a member, please visit MLCommons.org.