
Introduction
Scaling compute, guided by neural scaling laws, has dramatically reduced the need for manual feature engineering in natural language processing (NLP) and computer vision by using large-scale attention-based transformer models to automatically learn rich representations from data [1][2]. A similar trend is transforming deep learning-based recommendation systems, which have traditionally relied on architectures built from multi-layer perceptrons (MLPs), graph neural networks (GNNs), and embedding tables [3][4][5]. Recently, large sequential and generative models have been successfully deployed in online content recommendation platforms, delivering substantial improvements in model quality [5][7][8][9][10][11][12][13]. Given the global scale and importance of recommendation systems [6], incorporating such large-scale sequential recommendation models into the MLPerf Inference benchmark suite helps support ongoing infrastructure development.
We introduce DLRMv3, the first sequential recommendation inference benchmark in MLPerf’s DLRM family. DLRMv3 is built around an HSTU-based [5] architecture for ranking, capturing the dominant compute patterns of modern recommendation workloads: long input sequences, attention-heavy computation, and large embedding tables. Compared to the existing DLRM benchmark (DLRMv2 [14]), DLRMv3 increases the model size by 20X from 50GB to 1TB and raises the per-candidate compute by 6500X from 40M FLOP to 260 GFLOP over a span of just three years, aligning the MLPerf Inference suite with contemporary production-scale recommendation workloads, highlighting the increasing demand for compute. This higher compute regime is motivated by reported HSTU scaling behavior where higher model compute yields improved recommendation quality in production, enabling realistic resource burden–accuracy trade-off evaluation.
Task selection
Modern recommendation systems are typically deployed as multi-stage pipelines that separate candidate retrieval from ranking and, in some cases, additional refinement stages such as re-ranking or business-logic post-processing [15][16]. In a common design, a retrieval model first selects a small subset of relevant items from a very large corpus, optimizing for high recall, coverage, and strict latency and memory constraints at scale [15][7]. A downstream ranking model then scores these candidates using richer features and a more expressive architecture, optimizing for fine-grained user engagement metrics (e.g., click-through rate (CTR), watch time, satisfaction) under somewhat looser but still production-critical latency and throughput constraints [15][16][18]. This separation of stages is now standard in large-scale industrial systems, including those used for web, video, and social content recommendation.
DLRMv3 focuses on the ranking stage of this pipeline. Ranking models typically dominate the overall ML compute budget in production recommendation systems and are a focus of innovation in model architecture (e.g., attention-based sequential models and larger embedding tables), making them especially relevant for hardware and systems benchmarking. Focusing on ranking also maintains continuity with prior MLPerf DLRM benchmarks which target click-through-rate prediction.
Formally, given a user’s interaction history (e.g., a sequence of previously viewed or engaged items) and a candidate item, the DLRMv3 model predicts the probability of a desired outcome such as a click, like, or watch. This probabilistic prediction task is directly aligned with earlier DLRM benchmarks, which also model CTR-style binary outcomes.
Model selection
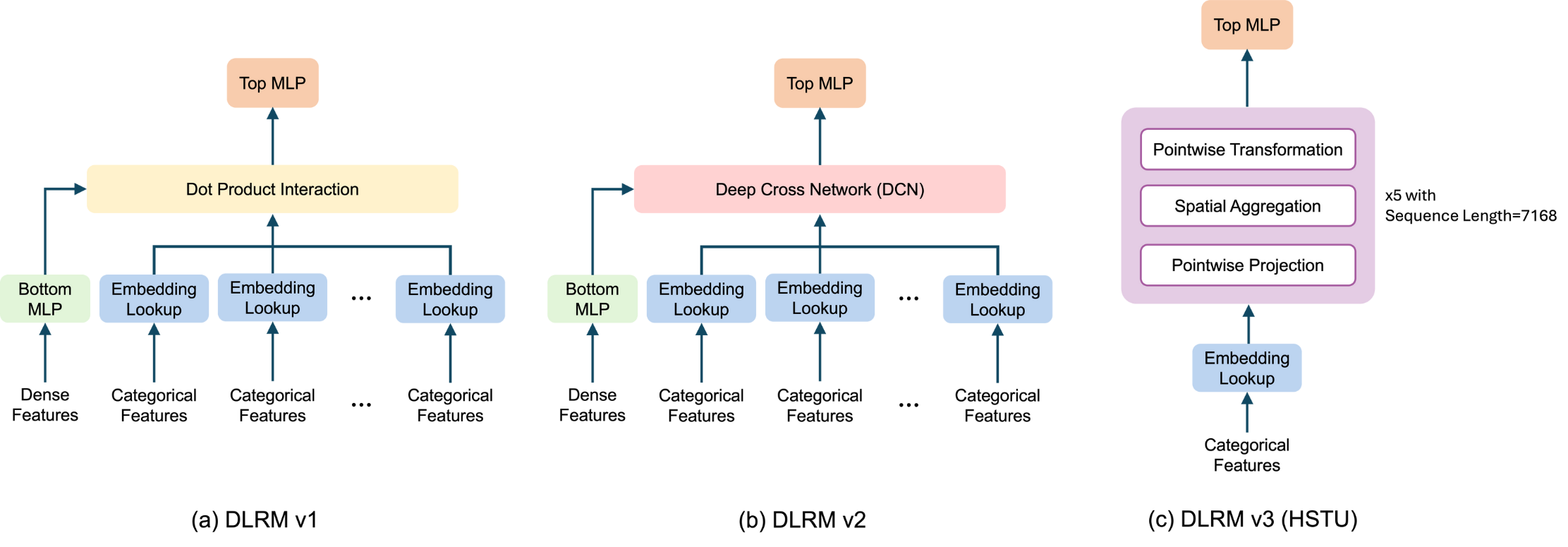
Figure 1. Model Architecture of different DLRM models.
We introduce an HSTU-based architecture as MLPerf’s third-generation deep learning recommendation benchmark (DLRMv3). In the DLRM lineage, DLRMv1 is built from MLPs and embedding tables with simple dot-product feature interaction, and DLRMv2 adds a deep-cross network component for richer explicit feature crossing. DLRMv3 introduces a new sequential feature transformation, interaction, and extraction component based on the hierarchical sequential transduction unit (HSTU) [5] while retaining a single, large embedding table and a top MLP for final prediction (Figure 1(c)).
HSTU-style architectures have been shown in production systems to effectively model long user interaction histories and improve recommendation quality relative to traditional MLP/DCN-based models at comparable or higher compute resources. They also reflect a set of compute characteristics that increasingly dominate modern recommendation inference—long sequences, attention-heavy computation, and large embedding tables—making HSTU a representative and forward-looking choice for a system-level benchmark.
In the table below, we compare model configurations among different generations of DLRM. The 260 GFLOP is computed as 2 * layers * (UIH_length * UIH_length * EmbDim / 2 + UIH_length * EmbDim * EmbDim * 4 + UIH_length * EmbDim * EmbDim * 3), which accounts for attention FLOP as well as the pre- and post-attention GEMMs. Note that this 260 GFLOP “per-candidate” number is an effective normalization: in a typical ranking request, the HSTU encoder processes the shared user-interaction-history (UIH) sequence once, and its output is reused when scoring a candidate set (2K candidates in DLRMv3), so the dominant UIH encoding computational cost is amortized across candidates rather than repeated 2K times. Moreover, because DLRMv3 uses a streaming time-series setup, deployments can reuse UIH-related KV states across consecutive timestamps for the same user, avoiding recomputation of the UIH encoding and reducing redundant dense compute by roughly 80–90% in steady state.
| Model/Input Configurations | DLRMv1 | DLRMv2 | DLRMv3 |
| Dense Inputs | 13 values | 13 values | 0 values |
| Sparse Inputs per candidate | 26 features, 208 lookups | 26 features, 214 lookups | 1 main feature, ~7K lookups |
| Embedding Tables | 26 tablesTotal hash size: 200MEmbDim: 128 | 26 tablesTotal hash size: 200MEmbDim: 128 | 1 main tableHash sizes: 1 billionEmbDim: 512 |
| Feature Interaction | Dot interaction using no trainable parameters | 3 layers of LowRank DCN | 5 HSTU layers, with user interaction history sequence length ~7K |
| Embedding table size (float16 datatype) | ~50GB | ~50GB | 1TB |
| FLOP per candidate | ~5 MFLOP | ~40 MFLOP | ~260 GFLOP |
To better align DLRMv3 with MLPerf Inference benchmarking goals and practical constraints, we introduce two intentional deviations from the original HSTU paper setup. These changes are motivated by the need for hardware-friendly, widely implementable benchmarking that still captures the important compute patterns of sequential recommendation models.
Action embedding preprocessing: The original HSTU model uses contextual interleaving of action embeddings, where contextual features and user actions are interleaved in the input sequence. This arrangement provides richer context to the model to learn dependencies between user behavior and item features. However, interleaving doubles the effective sequence length, which in turn significantly increases the computational cost. In DLRMv3, we omit action interleaving in the baseline and instead use a simplified input sequence where action embeddings are directly combined with contextual embeddings without expanding the sequence length. We choose this design because 1) the synthetic benchmark dataset (detailed in the next section) is intended for performance measurement and does not contain a sufficiently rich set of action features to justify the added modeling complexity and doubled sequence length, and 2) the non-interleaved option provides a more balanced accuracy–efficiency tradeoff that is appropriate for a standardized inference benchmark.
Time/position encoding: The original HSTU model uses a relative positional bias in the attention mechanism, implemented as Mask(SiLU(QKT)+bias)V, which helps capture relative temporal relationships between tokens and can improve accuracy. DLRMv3 instead adopts absolute time/position encoding, where a position-dependent bias is added to the query, key, and value vectors, and attention is computed as Mask(SiLU(QKT))V. We use absolute bias because relative bias introduces kernel optimization challenges and can slow down attention computation on many processors, whereas absolute encodings are widely supported, easier to optimize, and yield more predictable performance.
Dataset selection
Unlike DLRMv1 and DLRMv2, DLRMv3 formulates recommendation as a sequential transduction task over long user interaction histories and a very large item set. To be representative of modern production workloads, a suitable benchmark dataset needs to satisfy several properties simultaneously: (1) reasonably long user-interaction histories per request (thousands of events), so that sequential models and attention layers are meaningfully exercised; (2) a very large item set, consistent with the single large embedding table used in DLRMv3 (hash size on the order of one billion); and (3) a streaming structure, where the items viewed by a given user and the user’s preferences evolve over time and inference requests can be replayed in timestamp order. To the best of our knowledge, no existing public recommendation dataset provides all of these characteristics at the required scale.
For this reason, DLRMv3 uses a synthetic dataset specifically designed to match the model and system characteristics of large-scale sequential recommendation. The generator simulates five million users interacting with a billion items over time. Items are partitioned evenly into 128 categories, and each user is randomly assigned four categories that define their long-term interests. We generate 100 timestamps per user. The first 90 timestamps are used for training, and the remaining 10 timestamps are reserved for inference. For each user and each timestamp, with 70% probability, we generate a user interaction history (UIH) and a candidate sequence, and with 30% probability, the user has no request at that timestamp. The average UIH sequence length per (user, timestamp) is approximately 100, and the candidate sequence length is 2K. The generated sequences respect the streaming setup: at earlier timestamps, only a prefix of item IDs in each category can be sampled, and the maximum reachable ID grows linearly over time, mimicking new items entering the system.
When generating each user’s sequence, item categories for each position are sampled using a Dirichlet-process-style mechanism, following the generation algorithm in Section C of [5]. This setup yields a “rich get richer” dynamic where previously visited categories are more likely to be revisited. For each sampled category, item, and timestamp, we generate a continuous user-item rating (used as an action feature) by combining (1) a category- and time-dependent rating profile that varies smoothly over time via cosine functions with (2) an intrinsic per-item rating drawn once from a global 1-5 distribution representing item quality. The final rating is their average and is then used to derive labels for prediction.
Before converging on the streaming generator described above, we also experimented with the fractal expansion [19] approach for scaling the user-item interaction matrix from a smaller dataset. In brief, fractal expansion applies randomized kronecker products to a small interaction matrix to increase the dataset size while certain static structural properties (e.g., item popularity distribution and user engagement distribution) are preserved. However, fractal expansion is fundamentally designed for static datasets and does not naturally produce the streaming structure required by DLRMv3. In particular, DLRMv3 needs temporally ordered requests with evolving user histories and an expanding reachable item universe (to mimic new items entering the system) so that inference can be replayed in timestamp order. Fractal expansion does not inherently model properties such as per-user sequences over time and preference drift. Due to this fact, we did not select fractal expansion for DLRMv3 and instead designed a generator that simulates the streaming and sequential characteristics of online recommendation workloads.
Checkpoint Training
During the benchmarking creation process, we decided to use a 1TB float16 embedding table to store the one-billion item set in order to reflect the production use cases for such a model. This checkpoint is later trained on a single NVIDIA HGX B200 with eight GPUs and the fully open-sourced Generative Recommenders repo. Because each B200 has 180GB HBM capacity, the 1TB item table can be fully sharded to eight GPUs with enough capacity remaining in the GPUs’ HBM to store weights, activations, and gradients for the training loop to run.
Performance and accuracy metrics
The performance metrics chosen for the DLRMv3 benchmark follow the MLPerf Inference conventions and are closely aligned with those used for DLRMv2:
- Offline scenario: Query processing throughput measured as queries per second (QPS) with no latency constraint beyond completing the full query set as quickly as possible.
- Server scenario: QPS measured under an end-to-end latency constraint on the system under test (SUT) reflecting an online serving environment where requests arrive over time and must be processed under strict tail-latency targets.
To better reflect real-world deployment demands for large-scale recommendation ranking, we set the 99th-percentile SUT latency threshold to 80 ms in the server scenario.
Unlike other MLPerf Inference benchmarks, DLRMv3 uses a streaming setup with explicit timestamped requests. As a result, there is a request ordering constraint: requests associated with earlier timestamps must be served before those with later timestamps. Because MLPerf LoadGen does not natively enforce temporal ordering, this constraint may need to be implemented via SUT-side scheduling or request handling logic to ensure that streaming semantics are preserved while optimizing for throughput and tail latency.
For accuracy verification, we provide a trained reference checkpoint with a model size of 1TB in float16. Accuracy is evaluated on 0.1% subset of the inference dataset, comprising 34,996 requests across 10 inference timestamps. We report normalized entropy (NE), accuracy, and area under the ROC curve (AUC) as the primary quality metrics. For the reference implementation, the observed metrics are:
NE: 86.69%,
Accuracy: 69.65%,
AUC: 78.66%.
These values serve as the target baseline for accuracy compliance in the DLRMv3 benchmark. For accepted submissions, all three metrics (NE, Accuracy, AUC) must be within 99.9% of the reference implementation values.
Reference implementation
We provide a reference implementation of the DLRMv3 benchmark at
https://github.com/mlcommons/inference/tree/master/recommendation/dlrm_v3. The reference implementation covers model implementation, synthetic data generation, and performance/accuracy evaluation under the MLPerf Inference rules, as detailed below:
Model implementation: we provide a PyTorch implementation of the DLRMv3 HSTU-based ranking model, including a large embedding table consistent with the 1B-hash and 512-dimension configuration, a HSTU sequential encoder stack with the DLRMv3 design choices, and customized Triton kernels for HSTU operations.
Synthetic data pipeline: we provide the synthetic data generation script as well as a streaming data loader that constructs per-request model inputs (user interaction history + candidate set) and labels, matching the benchmark specification.
Reference benchmark: the reference benchmark contains three main runtime components:
- Data producer: this part takes in sample/request ID and performs batching and outputs item IDs of batched samples. This part is executed on the CPU, and the reference implementation supports both single- and multi-threading in Python.
- Sparse forward: this part takes in item ID lists and outputs embedding lookup outputs. This part is executed on the CPU, as datacenter systems typically contain large CPU memory to store the 1TB embedding table. The reference implementation uses PyTorch’s default embedding lookup operation without any quantization (in the float16 datatype). The implementation serves as a baseline for future improvements, e.g. distributed embedding lookup, GPU lookup, etc.
- Dense forward: this part takes in batched embeddings and runs the HSTU encoder forward in the bfloat16 datatype to generate predictions. The implementation employs data parallelism across GPUs on a single host by distributing input batches to eight GPUs using Python multi-processing. On each GPU, the implementation uses customized Triton kernels to improve efficiency. This implementation serves as a baseline for future improvements, including more efficient kernels and low-precision quantization.
To illustrate the performance of the DLRMv3 reference implementation, we report end-to-end results for different numbers of NVIDIA H100 GPUs on a single host with batch size equal to 10. In each configuration, we increase QPS until the system approaches saturation while still maintaining reasonable latency.
| #GPUs | QPS | Avg query time | P50 | P80 | P90 | P99 |
| 1 | 300 | 78ms | 74ms | 86ms | 99ms | 130ms |
| 2 | 500 | 86ms | 75ms | 85ms | 101ms | 285ms |
| 4 | 800 | 70ms | 69ms | 79ms | 85ms | 100ms |
| 8 | 1000 | 60ms | 60ms | 64ms | 67ms | 82ms |
A breakdown of query time at 8 GPUs highlights where time is spent in the baseline:
| Query time | Batch queueing time | Batching time | Sparse time | Dense time | ||
| CPU embedding lookup | H2D | GPU time | CPU overhead | |||
| 60ms | 11ms (18%) | 2ms (3%) | 3ms (5%) | 15ms (25%) | 26ms (43%) | 3ms (5%) |
The results show sub-linear scaling in throughput (QPS) with up to eight GPU devices: going from one to eight GPUs increases QPS by 3.3X (300 to 1000), while average latency drops from 78 ms to 60 ms. At eight GPUs, the end-to-end P99 remains slightly above 80 ms due to batching, data movement, and Python/CPU-side overheads. This outcome is expected and consistent with the goals of the reference implementation. The current code is a Python-based baseline, not an aggressively optimized C++/production server, and it is explicitly not targeting the best possible performance. The numbers therefore demonstrate substantial headroom for submitters to optimize request scheduling, embedding placement, kernel optimization, and inference-server integration to satisfy the P99 latency constraint.
Optimization opportunities
DLRMv3 is intentionally designed to expose multiple layers of optimization opportunities across the inference stack–from the serving framework to dense and sparse kernels to KV-cache-aware scheduling. The reference implementation provides a clear but unoptimized baseline in several of these dimensions, leaving room for submitters to explore system and kernel improvements while preserving accuracy.
Inference server library. The current reference pipeline is implemented in Python with a simple CPU/GPU orchestration model. In production, ranking models of this scale are typically deployed behind high-performance inference serving frameworks. There is significant room to improve request batching, thread and stream management, and SUT-side scheduling by integrating with an optimized inference server library.
KV cache integration. DLRMv3’s sequential HSTU architecture naturally supports KV caching, and there are two main dimensions where caching can yield meaningful gains:
- In-request cache (M‑FALCON-style microbatching). As discussed in the HSTU paper [5], when serving large candidate sets (e.g., >1K candidates), M‑FALCON applies microbatching over the candidates while reusing the KV cache for the shared user interaction history. This strategy does not change the model’s FLOP count requirements or accuracy, but it can materially improve performance by amortizing candidate processing and overlapping CPU and GPU work within a single request. In a DLRMv3 setting, this arrangement can reduce per-request latency without altering the underlying model.
- Across-request cache. For users who appear in multiple timestamps (as in the DLRMv3 streaming setup), the KV cache corresponding to their user interaction history can be reused across requests. This avoids recomputing the UIH encoding for each timestamp, reducing redundant FLOP by around 90% and improving both throughput and latency. Careful cache management and invalidation policies are needed to ensure correctness under streaming semantics.
Together, in-request KV microbatching (M‑FALCON style) and across-request KV caching offer complementary optimization levers: the former amortizes compute over large candidate sets and enables finer-grained CPU/GPU overlap within a request, while the latter reduces repeated UIH compute across consecutive requests from the same user. The reference implementation does not yet exploit these techniques, leaving them as explicit optimization opportunities for submitters targeting high-performance DLRMv3 deployments.
Dense optimization. The dense path in the reference implementation (HSTU encoder + top MLP) already uses Triton kernels and bf16, but there is still substantial room to improve. Further optimizations could include:
- more efficient attention and feed-forward kernels tailored to DLRMv3’s sequence lengths and dimensions;
- better utilization of vendor-specific libraries and exploration of lower-precision formats (e.g., FP8, INT8) under acceptable accuracy loss.
- optimized multi-GPU scaling within a node via improved load balancing, overlapping of data transfers with compute, and more sophisticated pipeline parallelism.
Sparse optimization. The sparse forward stage currently uses TorchRec embeddings on the CPU, with bf16 and no quantization, to support 1TB size in a simple, portable way. This is a natural baseline, but production systems often employ a combination of GPU-based embedding lookup, distributed sharding, hierarchical caching (e.g., HBM + DRAM), and quantization/compression. Submitters can explore moving embedding tables to accelerators, applying different types of quantization, or introducing model-parallel embeddings, as long as DLRMv3 accuracy targets are met. Improving the embedding pipeline can reduce end-to-end latency and CPU bottlenecks for large-scale deployments.
Conclusion
DLRMv3 extends the MLPerf Inference recommendation suite into the regime of large-scale sequential models, matching the size, structure, and serving patterns of the state-of-the-art production systems. By combining an HSTU-based ranking architecture, a billion-item synthetic streaming dataset, and a reference implementation that cleanly separates sparse and dense computation, DLRMv3 exposes the challenges of modern recommender inference: long user histories, attention-heavy sequence modeling, massive embeddings, and tight tail-latency targets under streaming workloads.
Notably, DLRMv3 increases the model memory footprint by 20X (from 50GB to 1TB) and the per-candidate compute by 6500X (from 40 MFLOP to 260 GFLOP) compared to DLRMv2, reflecting the rapid evolution of recommendation models over just three years. This dramatic scaling in compute and memory enables richer representations and more expressive models, ultimately delivering greater capability and accuracy to the community. By benchmarking these advances, DLRMv3 highlights how performance optimization is driving the frontier of recommender systems.
The benchmark is intentionally designed to leave room for innovation across hardware and software stacks–from inference servers and kernel optimizations to embedding pipelines and KV-cache-aware scheduling, while providing clear accuracy and performance baselines. We hope DLRMv3 will serve as a foundation for the community to evaluate, compare, and advance systems for next-generation recommendation workloads.
Contributors
Lucy Liao (Meta), Yu He (Stanford), Ze Yang (Meta), Zhao Zhu (Meta), Chunxing Yin (Meta), Rafay Khurram (Meta), Yuanjun Yao (Meta), Han Li (Meta), Daisy Shi He (Meta), Shilin Ding (Meta)
References
[1] Scaling Laws for Neural Language Models. https://arxiv.org/abs/2001.08361.
[2] Scaling Vision Transformers. https://arxiv.org/abs/2106.04560.
[3] Scaling Law for Recommendation Models: Towards General-purpose User Representations. https://arxiv.org/abs/2111.11294
[4] Understanding Scaling Laws for Recommendation Models. https://arxiv.org/abs/2208.08489
[5] Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations. https://arxiv.org/abs/2402.17152v2
[6] Recommender system is the single largest software engine on the planet — Jensen Huang. Q4’23 earning report. https://www.youtube.com/watch?v=txOv_pi-_R4&t=2020s
[7] LONGER: Scaling Up Long Sequence Modeling in Industrial Recommenders. https://arxiv.org/abs/2505.04421
[8] Towards Large-scale Generative Ranking. https://arxiv.org/abs/2505.04180
[9] MTGR: Industrial-Scale Generative Recommendation Framework in Meituan. https://arxiv.org/abs/2505.18654
[10] From Features to Transformers: Redefining Ranking for Scalable Impact. https://arxiv.org/abs/2502.03417
[11] Hi-Gen: Generative Retrieval For Large-Scale Personalized E-commerce Search. https://arxiv.org/abs/2404.15675
[12] HLLM: Enhancing Sequential Recommendations via Hierarchical Large Language Models for Item and User Modeling. https://arxiv.org/abs/2409.12740
[13] Recommender Systems with Generative Retrieval. https://arxiv.org/abs/2305.05065
[14] https://github.com/mlcommons/inference/blob/master/recommendation/dlrm_v2/pytorch/README.md
[15] Deep Neural Networks for YouTube Recommendations, https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45530.pdf
[16] Deep Learning Based Recommender System: A Survey and New Perspectives, https://arxiv.org/abs/1707.07435
[17] Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations, https://research.google/pubs/sampling-bias-corrected-neural-modeling-for-large-corpus-item-recommendations/
[18] Recommending What Video to Watch Next: A Multitask Ranking System, https://daiwk.github.io/assets/youtube-multitask.pdf
[19] Scalable realistic recommendation datasets through fractal expansions, https://arxiv.org/pdf/1901.08910