
Introduction
The Reasoning LLM Task Force was convened to ensure that the MLPerf® Inference v5.1 benchmarks address the evolving capabilities of advanced reasoning language models in real-world applications. Reasoning LLMs stand out for their mathematical, logical, and step-by-step problem-solving capacities. They are being deployed on the hardest use cases such as knowledge and reasoning, code generation and debugging, and math & science problem solving.
These models generate Chains of Thoughts as part of their responses; their output consists of reasoning tokens and output tokens. They benefit from large output lengths where the model is allowed to “think” longer by emitting more reasoning tokens, which typically constitute the bulk of the output generation. Performance evaluation considers the token generations from both reasoning and output tokens. However, only output tokens are used for the accuracy evaluation.
With the addition of DeepSeek-R1 671B (DS-R1) to the MLPerf inference suite, we focus on two key aspects:
Creating a first industry-standard benchmark for reasoning models
- Creating a first industry-standard benchmark for reasoning models
- Evaluate AI performance for long output sequence lengths required by reasoning LLMs
Model selection
DeepSeek-R1 671B (released in January 2025) is the flagship reasoning LLM from DeepSeek, fully open-sourced on HuggingFace. Published under an MIT license, it is a significant step forward for open-source reasoning LLMs, with scale and capabilities competing with state-of-the-art commercial offerings at the time.
Some key aspects of this model include:
- 671B total parameters, with 37B activated per-token and a maximum output length of 20K (the model may support higher lengths)
- The model is trained with a combination of cold-start supervised data and large-scale reinforcement learning, resulting in performance on par with the state of the art in math, code, and reasoning tasks
Popular use cases include:
- Step-by-step planning: DeepSeek-R1 excels at breaking down complex problems into actionable sub-steps, making it suited to workflow automation where clarity and logical progression are crucial for robust outcomes
- Knowledge & reasoning: Providing expert answers across diverse domains, synthesizing logic and concepts across fields like math, science, programming, and professional knowledge
- Generating & debugging code: Supporting technically demanding workflows that benefit from logical clarity and error resolution
Dataset and task selection
The dataset for benchmarking DeepSeek-R1 was curated to highlight advantages of a large reasoning model over traditional LLMs. With the chosen maximum output sequence length of 20K (the highest yet in the MLPerf Inference benchmark suite), DS-R1 is able to conclude its answer from long chains of thoughts and reasoning traces on the most challenging problems.
The MLCommons® task force integrated samples from a diverse mix of open datasets:
- AIME (1983–2024): link
These advanced high school mathematics problems trace their roots to the storied American Invitational Mathematics Examination, serving as a gold standard for mathematical reasoning assessment. Each problem was selected for its challenge level and capacity to test logical breakdowns, multi-step solutions, and mathematical creativity. The result is an expression or value and evaluation is via Exact-Match. - MATH500: link
A curated set of 500 multilingual math problems, designed to probe both computational accuracy and linguistic flexibility. The format ensures models are evaluated on diverse language inputs—crucial for international deployments—alongside pure reasoning skill. The result is a mathematical expression or a numerical value and evaluation is via Exact-Match. - GPQA-Diamond: link
This unique dataset features graduate-level multiple-choice questions in biology, physics, and chemistry, intentionally crafted to be immune to trivial lookup strategies. The content rigorously tests a model’s ability to synthesize scientific logic and demonstrate oversight rather than regurgitation. The result is a textual word in response to the question in the input sequence. Evaluation is via Exact-Match. - MMLU-Pro: link
Building on the original MMLU benchmark, MMLU-Pro ramps up difficulty by expanding answer choices and emphasizing reasoning-intensive queries across broader domains. It ensures models aren’t just strong in niche areas but can generalize across challenging, expert-level knowledge. The result is a specific choice among the multiple-choices presented to the model. Evaluation is via Exact-Match. - LiveCodeBench: link
Over 500 live-updating code competition tasks push models to parse, generate, and debug complex software solutions in real time. This dataset highlights logical planning, error identification, and the code reasoning demanded by modern technical workflows. The result is a code that solved the problem stated in the input. Evaluation is via code execution, passing test-cases and runtime constraints.
With mean input and output sequence lengths of 800 and 3,880 tokens, respectively, the DS-R1 dataset highlights the model’s ability in parsing proficiency, contextual linking, and synthesizing insights from complex and lengthy inputs.
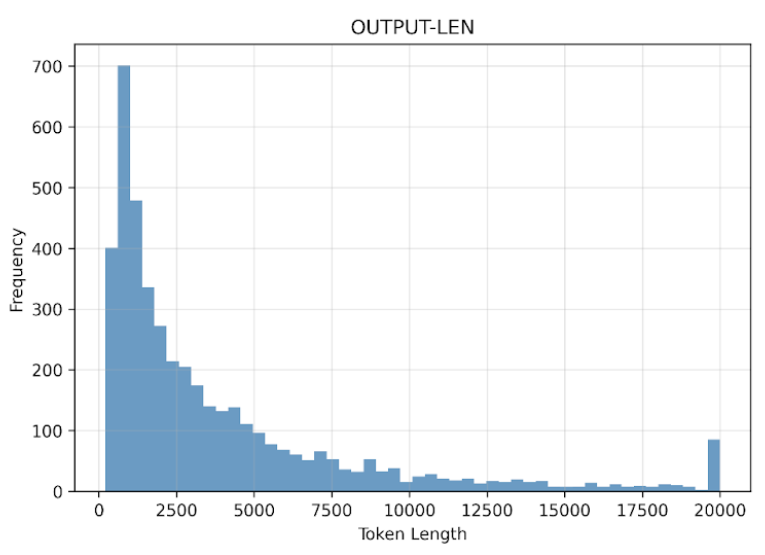
Performance metrics
The performance metrics chosen for the DeepSeek-R1 benchmark are the same as those used for the Llama 2 70B benchmark in MLPerf Inference v4.0: (1) token generation throughput for the offline scenario and (2) token generation throughput while constrained by Time To First Token (TTFT) and Time Per Output Token (TPOT) for the server scenario. For more information, please refer to the “Measuring performance of the LLM” section of “Llama 2 70B: An MLPerf Inference Benchmark for Large Language Models” on the MLCommons website.
To reflect the demands of real-world deployment, we set the 99th percentile TTFT threshold to two seconds and the 99th percentile TPOT threshold to 80 ms. These thresholds reflect the computational challenges of deploying large reasoning models with a large thinking budget while maintaining reasonable responsiveness.
Accuracy metric
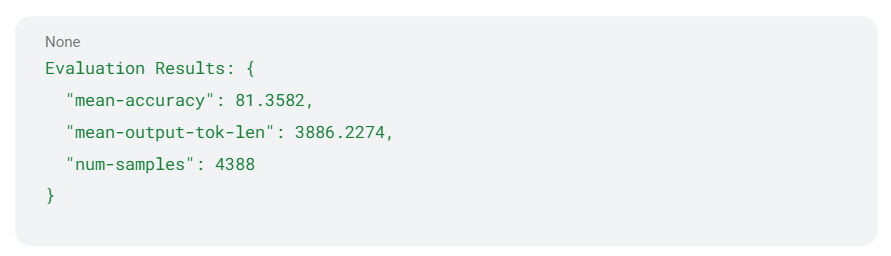
The DS-R1 benchmark employs task-specific accuracy metrics to evaluate performance across the dataset. Exact match to ground truth is used for multiple-choice style questions (GPQA-Diamond, MMLU-Pro) and math/numerical questions (AIME, MATH500). For code generation (LiveCodeBench), we evaluate the generated code using a code-evaluation framework and test cases. The accuracy threshold for closed division submissions is set to 99% of the FP8 reference.
( See https://github.com/mlcommons/inference/tree/master/language/deepseek-r1 )
The reference implementation for DeepSeek-R1 leverages PyTorch and the official DeepSeek-R1 inference code. Three backends are provided (vLLM, SGLang and PyTorch) to support a wide range of AI processors.
Reference implementation
The reference implementation for DeepSeek-R1 leverages PyTorch and the official DeepSeek-R1 inference code. Three backends are provided (vLLM, SGLang and PyTorch) to support a wide range of AI processors.
For readers interested in running the model themselves, we encourage them to follow the reference implementation, which contains the code and the instructions on how to run the entire end-to-end benchmark.
Conclusion
The usage of LLMs is expanding rapidly across a diversity of application domains, with a demand for LLMs at different scales and response latencies with large sequence lengths. MLPerf is keeping pace with these trends by introducing a very large scale 671B-parameter reasoning benchmark in the new MLPerf Inference v5.1 release.
In this post, we shared the motivation and the complexities involved in the choice of model, task, dataset, accuracy, performance, and verification of such LLM benchmarks. We believe the design choices of this benchmark objectively address most of the critical deployment decisions faced by practitioners while delivering important performance insights to customers. With the addition of this benchmark to MLPerf Inference, we now offer a comprehensive suite of language benchmarks at all scales (7B to 671B), diversity of architectures (including mixture of experts (MoE) models), types (reasoning and non-reasoning), and deployment scenarios (datacenter, edge, or low latency).
Details of the MLPerf Inference DeepSeek-R1 benchmark and reference implementation can be found here.