Over the past 10 years, machine learning (ML) has grown exponentially, from a small research field to a broad community spanning universities, technology platforms, industries, nonprofits, and governments. The global funding (PE/VC) in AI companies increased by 390% from $16 billion in 2015 to $79 billion in 2022.[1] Recent advances in ML have made it possible for machines to not only consume but also create content to a level that approaches what humans can do. This capability is sometimes called Generative AI[2]. This is primarily enabled by foundation models[3] – large, pre-trained models trained on copious amounts of diverse data through self-supervised learning that can be adapted to a wide array of downstream tasks. The disruptive potential of foundation models lies in their ability to achieve state-of-the-art performance on tasks with little or no task-specific training required (though such “fine-tuning” further improves capabilities).
While considerable innovation is taking place across the ML research-to-production life cycle, it often occurs organically and in silos, resulting in uneven impact and a low transfer of innovation across industry verticals. A handful of technology companies are experiencing benefits from deploying cutting-edge ML at scale, while others are still learning to operationalize it: to quote one study, nearly 80 percent of AI solutions are abandoned because companies struggle to scale them.[4] Even in companies with advanced ML capabilities, there is considerable friction and uncertainty within the ML development cycle. Reasons for this include:
- ML has a fundamentally different programming paradigm than traditional software. In traditional software engineering, a programmer writes explicit instructions for the computer to execute, while in machine learning—especially for deep neural networks—the programmer provides a data set and specifies a model architecture and other training code from which the program learns the desired behavior. While this is an incredibly powerful programming tool, it creates an inherent unpredictability that must be accounted for throughout the ML development life cycle.
- The ML programming paradigm requires a very different development cycle. The best practice for traditional software development uses a collaborative, flexible, agile methodology and the scrum framework, whereby teams make rapid, incremental advancements toward well-defined goals. ML development, by contrast, is relatively opaque and unpredictable; in effect, data is the new code, and the quality and quantity of data determine the ML’s functionality—though this connection is still poorly understood. Teams continuously revisit data sets and retrain models as they move ML innovations from research into production – a process we term the “ML development flywheel” (Exhibit 1).
- ML lacks a mature ecosystem – a set of shared tools, resources, standards, and best practices – to support this development cycle. Traditional computer programming has had decades to develop an ecosystem that has become so prevalent that nearly 80 percent of all sites on the internet today rely on a common software stack[5]. ML development, however, is still considered an art as much as a science, often requiring a custom solution for each new problem and highly experienced engineers who can try various techniques gained through experience to arrive at the desired model behavior and convergence.
Exhibit 1: ML Development Flywheel
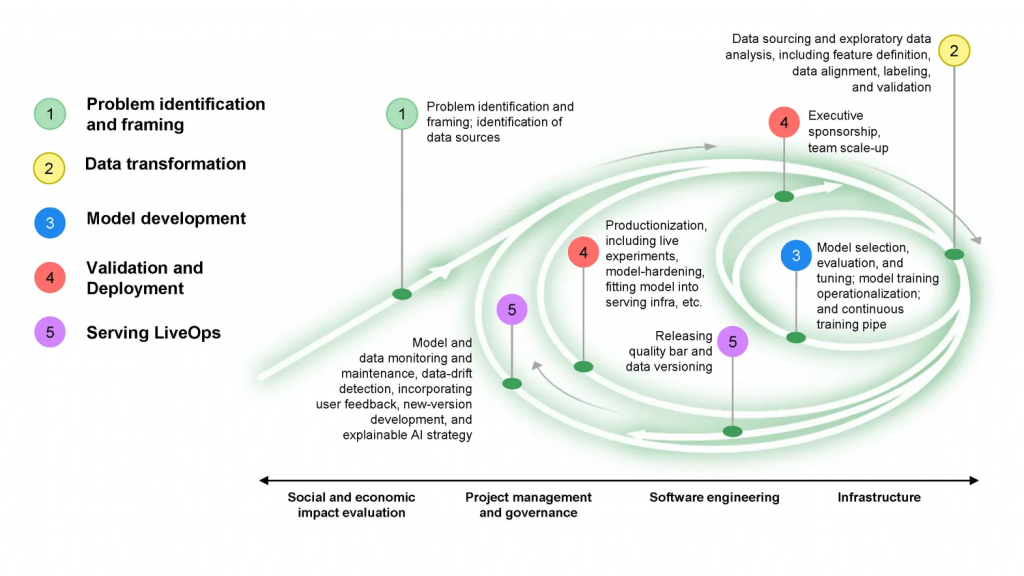

The result is that the ML field today resembles the internet of the late 1990s. It has high potential but uneven impact, knowledge is spread across myriad organizations and individuals, and programming requires a collection of custom, often vertically integrated tech stacks.
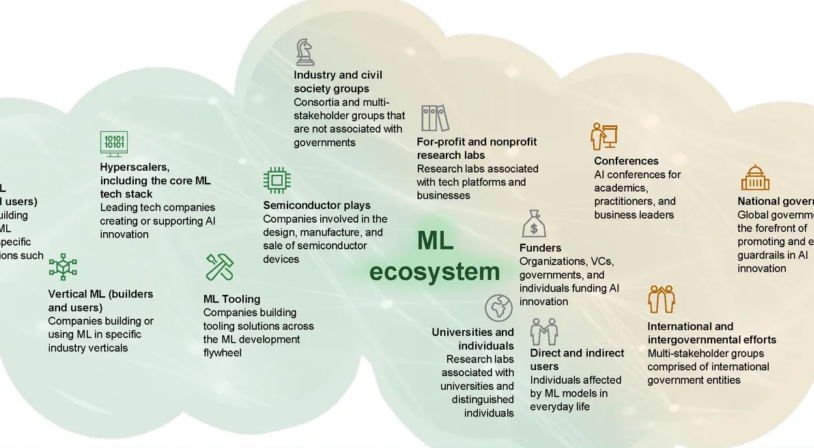
Motivated by the challenge of increasing ML’s impact in society, the MLCommons Association collaborated with several partners on a high-level analysis of how to develop a healthier ML ecosystem (Exhibit 2). We wanted to answer two key questions—where are the opportunities for unlocking ML’s greatest impact on society, and what are the best ways to address them—with the goal of providing a perspective on how various ML ecosystem players, including enterprises and technology hyperscalers,[6] can contribute to driving greater ML adoption.
Exhibit 2: Types of ML Ecosystem players
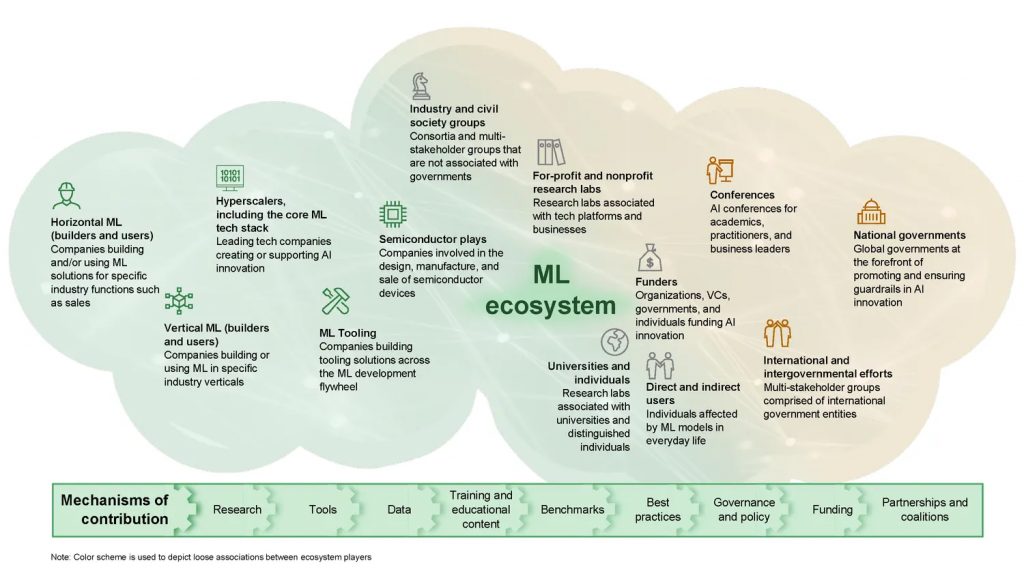
We interviewed 32 experts across these ML ecosystem players[7]—including engineers and product managers from leading tech companies, business leaders, the heads of industry and civil-society groups, and academics—to explore the challenges they face in developing ML and attempt to prioritize solutions for addressing them.
Opportunities to improve ML
Exhibit 3: Opportunities to improve ML fall into three broad categories
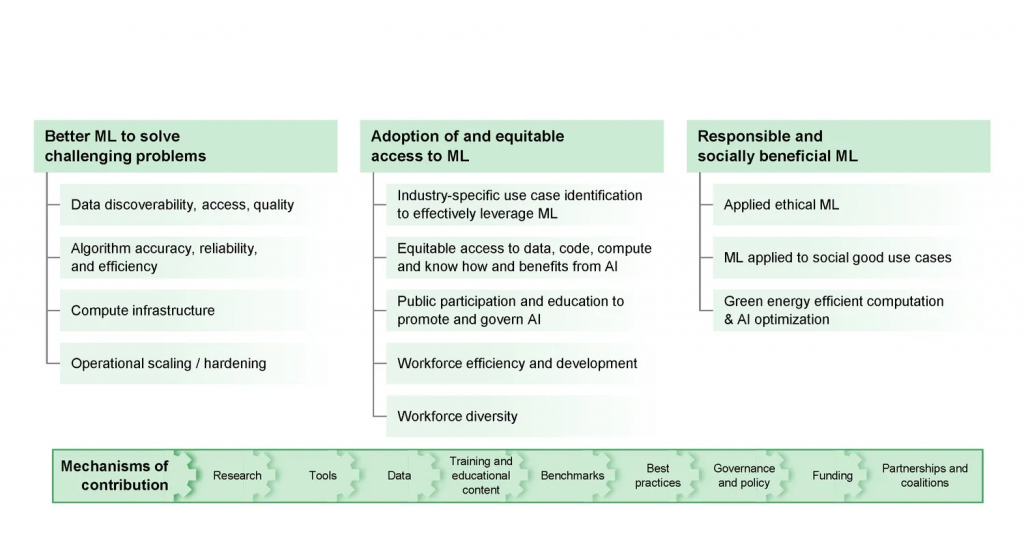
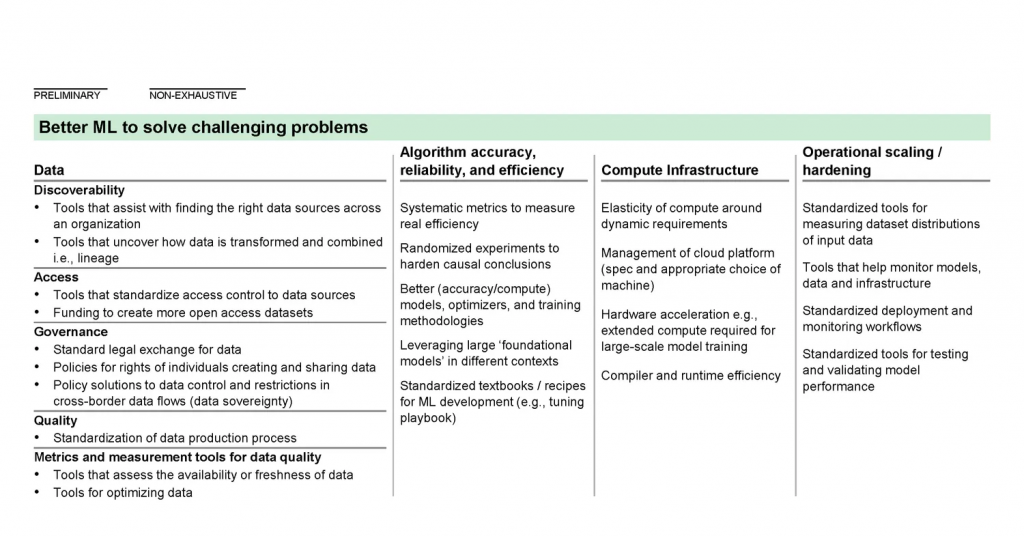

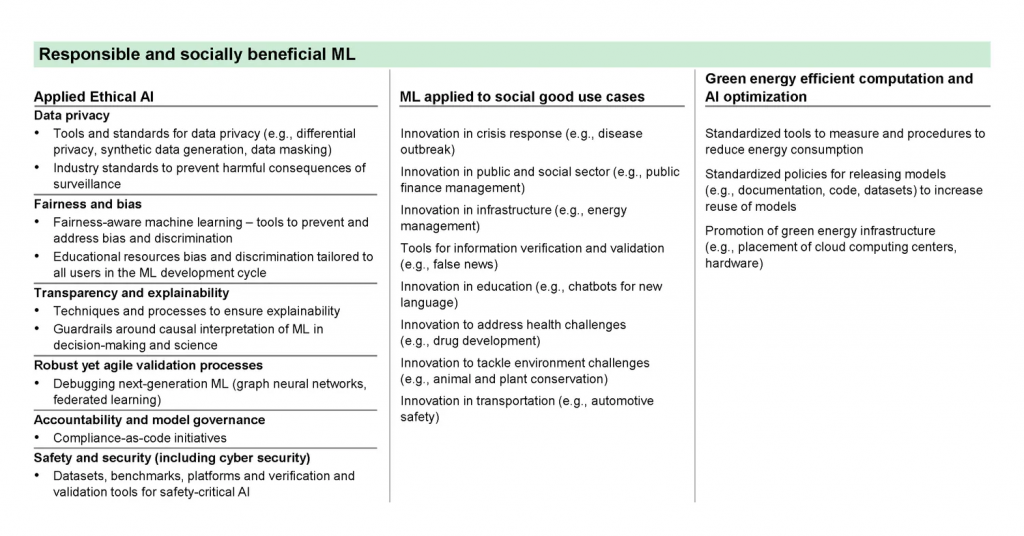
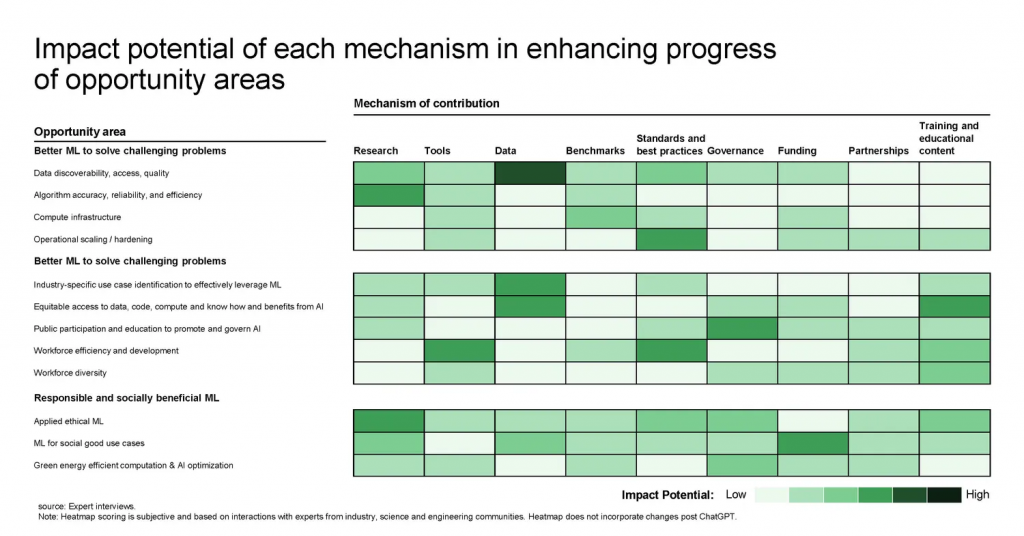
Opportunities to unlock the full impact of ML at scale fall into three categories: increasing the capabilities of ML technology, broadening access to and adoption of ML, and ensuring that the results of ML benefit society (Exhibit 3). All ecosystem players have a role to play for ML to reach its full potential, and contributions can be in the form of tools, data, funding, education, training, benchmarks, best practices, partnerships and coalitions, and governance and policy.
Deep dives on critical ecosystem areas to improve
In this section, we discuss three key opportunities that emerged in our discussions with business leaders and ML practitioners: data discoverability, access, and quality; operational scaling and hardening; and ethical applied ML.
Data discoverability, access, and quality: ML developer productivity is data-limited, but public data is primitive and data tools are poor
ML developers face two broad categories of data challenges:
- Finding, accessing, and labeling data. Developers need to locate relevant data, gain access to it—which can be especially difficult if it’s held by multiple organizations—format it for consistency, and sometimes efficiently and correctly label it.
- Making data useful. Collected data can be incomplete, incorrect, biased, or misleading in numerous ways, problems which are hard to detect prior to deployment.
These challenges are exacerbated by the relatively low investment companies are making in public ML data (compared with the substantial investment in model development), the nonexistent to primitive nature of metrics and standards for ML data sets, and the lack of a widely used tool stack for working with data. Opportunities for improving the ML data ecosystem include:
- Improving public data sets. There is opportunity for a network of partners to work together to create open data sets that support multiple contributors and continuous quality improvements. Datasets such as the Pile[8] and LAION[9] are early, promising examples of the potential of this approach, though other issues such as licensing still need to be addressed. One estimate states that the boost to the economy from adoption of open-data ecosystems in finance could range from about 1 to 1.5 percent of GDP in 2030 in the European Union, the United Kingdom, and the United States, to as much as 4 to 5 percent in India.[10] There is a particularly strong need for open datasets that define community consensus on usable public data, serve as tests and benchmarks for different approaches, or address societal issues without commercial interest.
- Increasing data sharing. Public data sets should be populated by standardizing best practices for anonymizing and releasing data or finding innovative ways to leverage private data without releasing it. For example, MedPerf is an open framework for benchmarking machine learning in the medical domain that securely evaluates medical AI models on distributed healthcare data sets while keeping the data private.[11]
- Agreeing on common data metrics and standards. First, metrics, such as DataPerf, should be created that quantify data quality (DataPerf is a benchmark suite for ML datasets and data-centric algorithms[12]). Second, data formats and metadata content should be standardized; Google model cards, IBM fact sheets, datasheets for datasets, and the Data Nutrition Project all provide examples of how to do this.[13] Third, best practices for ethical data sourcing and consistent licensing should be developed.
- Improving interoperable data-centric tools. These metrics and standards should be leveraged to improve data quality and reduce costs through a data-development stack of interoperable tools akin to those widely used for code.

Operational scaling and hardening: deploying models from research into production too often relies on costly and fragile bespoke solutions
Delivering stellar results using a prototype model trained on an experimental data set is a significant accomplishment, but putting the model into production to deliver business value brings new challenges that generally fall into two categories:
- Building the ML data platform. Experimental data is often hand-curated or has different characteristics from the actual, production data at a company. As a result, teams need to invest in building persistent pipelines to access and transform production data and design features to approximate those used for the experimental model. Often the new model does not match the evaluation performance of the experimental one and additional work is needed to bring it up to par. An abrupt handoff between the research and production teams can increase the challenge of this work if the team responsible for operationalizing the model into a product is unaware of the context and datasets used in model development. Finally, live data needs to be collected as the model is put through dark launches, live experiments, and full launch, all while monitoring the model output to ensure the query and training distribution match, and it isn’t producing unintended outcomes. Building this end-to-end data story, with an ability to track artifact provenance, requires significant up-front investment before any business impact is realized.
- Navigating infrastructure fragmentation. Much of the open-source infrastructure used to write ML models and compile them down to hardware-native code was created by researchers for their own specific, fast-changing needs. This has resulted in an ecosystem of toolchains that is highly siloed or patched together using custom bridges, which creates a host of interoperability problems—for example, trying to port a server-side model written in Pytorch to a mobile back-end using TFLite can be a challenging process—and means teams often have to throw out their existing model code and pipelines and start from scratch as their business needs evolve, significantly slowing down development velocity.
ML tooling innovation is addressing some of these challenges, in the process attracting high levels of VC funding and some of the best talent in the industry. An ecosystem perspective suggests new solutions are needed to accelerate ML adoption:
- Data-platform standards and best practices. Best practices for building robust data platforms could enable a smooth transition from prototyping to live monitoring. While it is common for different companies to use different tools for each stage of the pipeline, data sharing and security standards would ensure these tools work seamlessly together.
- Standard interchange formats. Decoupling higher and lower parts of the core ML stack could drive interoperability and reduce fragmentation. Developers should be able to design the toolchain (for example, PyTorch framework with XLA compiler) that best meets their needs and works across hardware back-ends. Defining a standard set of operators at various levels of the stack would make ML development much more scalable and make it easier for hardware and software vendors to focus on their strengths rather than on needing to support multiple independent code paths.
- Include people and organizations. Promising ML applications often fail to gain traction for nontechnical reasons such as a lack of stakeholder involvement during development and skepticism by front-line users during early iterations. Organizations as a whole, not just ML engineering teams, need to be aligned around the ML development flywheel.

Ethical applied ML: developers lack universally accepted standards, technologies and benchmarks to build responsible ML applications
ML has driven phenomenal advances in many areas, from autonomous vehicles and drug discovery to financial fraud-detection and retail-product recommendations. However, it has also had negative effects, including perpetuating systemic biases[15], making many companies cautious about adopting it. Building a trust-based AI architecture will expand the scope of industries and use cases where ML can be applied and will require work across several dimensions – bias and fairness, explainability and transparency, human oversight and accountability, privacy and data ethics, performance and safety, security and sustainability[16]. These can be addressed through several approaches:
- Privacy-enhancing technologies. Many tech hyperscalers and open-source communities provide privacy-enhancing technology solutions, such as federated learning and homomorphic encryption, but these solutions lack standardization, which can lead to reinventing the wheel in silos rather than alignment among ecosystem players. A common set of community backed standards can help ensure these technologies are more widely adopted, benefiting everyone.
- Best practices. There is a need for universally accepted best practices so that organizations with hundreds of models can carry out the full gamut of fairness checks and evaluate data risks. Instituting best practices while the technology is still young can minimize problems caused by proprietary systems not “talking” to one another later, help standardize models, and contribute to curbing bias. Early development of such practices can help avoid what occurred with electronic health records; the promise was that they would help patients and providers easily access relevant information, but the reality is that records remain fragmented across platforms, often causing frustration for stakeholders at every level.
- Policy and governance. Global standards for AI regulation are still being developed and governments, technology companies, and civil society groups can help shape legislation to focus on key principles like transparency, human centricity, contestability, data protection, and fairness. For regulations already in place, there remains an opportunity to provide tools and certifications to help companies implement these guidelines.
- Tools and benchmarks. There is a need for comprehensive benchmarks tailored to the needs of specific industries for identifying and addressing bias. An example of this is the Monk Skin Tone Scale[17] developed and released by Google that can be leveraged to evaluate computer vision datasets and models for skin tone representation. There is also a need for better documentation and artifact tracking at each stage of the ML lifecycle.[18]
- Education and training. To accelerate the adoption of tools, benchmarks, and best practices, training resources should be customized to the needs and roles of each of the players involved in each step of ML development flywheel. One example of such a resource is provided by EDM Council, a global association focused on industry-validated trainings and certifications and other practitioner resources.

Concluding thoughts
The ML field is still nascent—barely 10 years old—and significant work is needed to transform it into an established discipline that achieves its full potential of social and economic impact. Mainstream ML adopters and tech hyperscalers will be key to this endeavor.
Key takeaways for Enterprise adopters of ML
In recent years, the momentum of R&D in AI has been exponential; more than 30 times as many patents were filed in the field in 2021 than in 2015.[19] Given this momentum, as well as other factors such as increased investment, AI is not only performing better but also becoming more affordable, leading to increased adoption across industries. According to McKinsey & Company’s Global Survey on the state of AI[20] 2022, 50 percent of respondents reported their organizations had adopted AI in at least one function in 2021, compared with 20 percent in 2017. While AI adoption has grown 2.5 times since 2017, it has more recently plateaued. While the consensus is that AI will be a mainstream technology at their companies, a 2020 survey found that only 76 percent of organizations were close to breaking even on their AI investments when considering the costs and not just the benefits.[21] To address these challenges and realize the full potential of AI for themselves and other ecosystem players, enterprise adopters could adopt the following strategies:
- Reassess the path to ML production. The path to performance observability and model conformance lies as much in the data that is fueling the infrastructure as it does in the design of the infrastructure itself. Thus, enterprise ML adopters should be as metrics-driven on evaluating data quality as they are on enabling high-performance hardware. This would enable the next level of scale and impact for enterprises. Enterprise adopters could work to prevent bias and drift by building in time for iterative, unpredictable developments and bringing in all relevant organizational stakeholders, including legal and ethics leads, early in the ML development flywheel. This would help organizations identify regulatory requirements up-front, mitigate bias, and communicate clearly about privacy and governance laws.
- Support emerging standards and best practices, and tailor them to current and future challenges. Many current ML development tools are either domain-specific or don’t scale well when moving from research prototyping to deploying ML at scale. Adopting open-source frameworks and best practices and eschewing one-off solutions can ensure an organization does not get stuck on a tech island as it matures but continues to learn and adapt as tooling solutions, policies, and innovations in the ecosystem evolve and scale.
- Invest in people. Today’s AI heroes are often just those who write model code. However, enterprises need to ensure that everyone involved in the ML Development Flywheel, such as those who enable the data flow, provide tooling solutions, assure unbiased outcomes, and monitor live operations are also rewarded and upskilled.

Key takeaways for tech hyperscalers
As some of the largest investors in ML research, infrastructure, and applications, tech hyperscalers such as Google and Meta are critical to advancing the ML ecosystem. In addition to the significant contributions they already make through university collaborations and open-source projects, we would encourage them to invest in the following:
- Support the development of public resources, especially data sets and tooling, to allow researchers to continue to innovate and communicate as ML technology advances.
- Contribute to legal and business best practices that help all companies use ML effectively and responsibly. This can be achieved by partnering with mainstream ML adopters to share best practices on translating business problems into ML solutions and providing a solid technical foundation for emerging regulatory frameworks.
- Work cross-organizationally or with industry groups to drive interoperability in open-source frameworks and tooling. This could enable more companies to participate in ML collaboratively and flexibly, growing overall adoption.
- Encourage efforts to raise public understanding and awareness of AI’s potential for positive societal impact, such as through research into AI applications for social good and efforts to reduce bias and increase inclusion.
- Be transparent about the limitations and risks of ML-based solutions.

Authors
Peter Mattson is a Senior Staff Engineer at Google. He co-founded and is President of MLCommons®, and co-founded and was General Chair of the MLPerf™ consortium that preceded it.
Aarush Selvan is a Product Manager at Google where he works on Natural Language Processing for the Google Assistant.
David Kanter is a co-founder and the Executive Director of MLCommons, where he helps lead the MLPerf benchmarks and other initiatives.
Vijay Janapa Reddi is an Associate Professor at Harvard University. His research interests include computer architecture and runtime systems, specifically in the context of autonomous machines and mobile and edge computing system.
Roger Roberts is a Partner at McKinsey & Company’s Bay Area office and advises clients in a broad range of industries as they address their toughest technology challenges especially in retail and consumer industries
Jacomo Corbo is Founder and co-CEO of PhysicsX, a company building AI generative models for physics and engineering; previously Chief Scientist and Founder of QuantumBlack and a Partner at McKinsey & Company
Authors would like to thank Bryan Richardson, Chaitanya Adabala Viswa, Chris Anagnostopoulos, Christopher McGrillen, Daniel Herde, David Harvey, Kasia Tokarska, Liz Grennan, Martin Harrysson, Medha Bankhwal, Michael Chui, Michael Rudow, Rasmus Kastoft-Christensen, Rory Walsh, Pablo Illanes, Saurabh Sanghvi, Stephen Xu, Tinashe Handina, Tom Taylor-Vigrass, Yetunde Dada, and Douwe Kiela as well as Adam Yala from University of California, Berkeley, Kasia Chmielinski from Data Nutrition Project and contributors from Google, Harvard University, Hugging Face, Meta AI, and Partnership on AI for their contributions to this article.
- Pitchbook ↩︎
- https://www.mckinsey.com/featured-insights/mckinsey-explainers/what-is-generative-ai ↩︎
- Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M. S., Bohg, J., Bosselut, A., Brunskill, E., Brynjolfsson, E., Buch, S., Card, D., Castellon, R., Chatterji, N., Chen, A., Creel, K., Davis, J. Q., Demszky, D., … Liang, P. (2022, July 12). On the opportunities and risks of Foundation models. arXiv.org. Retrieved January 20, 2023, from https://arxiv.org/abs/2108.07258 ↩︎
- “How to operationalize machine learning for maximum business impact: Frameworks for machine learning operationalisation are key,” Wired, in partnership with QuantumBlack, June 12, 2021, https://www.wired.co.uk/bc/article/mckinsey-machine-learning ↩︎
- “Usage statistics of PHP for websites,” W3 Techs, n.d., https://w3techs.com/technologies/details/pl-php ↩︎
- Tech hyperscalers comprises technology companies like Google, Microsoft, and Amazon that are making efforts to scale in software products and services but also expand to numerous industry verticals ↩︎
- Data Nutrition Project, Google, Harvard University, Hugging Face, Meta AI, Partnership on AI, and the University of California, Berkeley ↩︎
- https://pile.eleuther.ai/ ↩︎
- https://laion.ai/blog/laion-400-open-dataset/ ↩︎
- White, Olivia, Anu Madgavkar, Zac Townsend, James Manyika, Tunde Olanrewaju, Tawanda Sibanda, and Scott Kaufman. “Financial Data Unbound: The Value of Open Data for Individuals and Institutions.” McKinsey & Company June 29, 2021. https://www.mckinsey.com/industries/financial-services/our-insights/financial-data-unbound-the-value-of-open-data-for-individuals-and-institutions ↩︎
- Alexandros Karargyris et al., “MedPerf: Open benchmarking platform or medical artificial intelligence using federated evaluation,” n.d., https://arxiv.org/ftp/arxiv/papers/2110/2110.01406.pdf ↩︎
- https://dataperf.org/ ↩︎
- “The value of a shared understanding of AI models,” n.d., https://modelcards.withgoogle.com/about; Michael Hind, “IBM FactSheets further advances trust in AI,” July 9, 2020, https://www.ibm.com/blogs/research/2020/07/aifactsheets/; Timnet Gebru et al., “Datasheets for datasets,” Cornell University, March 23, 2018, https://arxiv.org/abs/1803.09010; “The Data Nutrition Project,” n.d., https://datanutrition.org/ ↩︎
- https://openai.com/pricing ↩︎
- Silberg, Jake, and James Manyika. “Tackling Bias in Artificial Intelligence (and in Humans).” McKinsey & Company, July 22, 2020. https://www.mckinsey.com/featured-insights/artificial-intelligence/tackling-bias-in-artificial-intelligence-and-in-humans. ↩︎
- https://www.mckinsey.com/featured-insights/in-the-balance/from-principles-to-practice-putting-ai-ethics-into-action ↩︎
- https://skintone.google/ ↩︎
- “Machine learning life cycle,” Partnership on AI, n.d., https://docs.google.com/presentation/d/1fh4AGTeXRN0hInvoZsYMz7Bb3mgzfZktdGZtKvBRED8/edit#slide=id.gdf40b9b06b_2_491 ↩︎
- Daniel Zhang et al., “Artificial Intelligence Index Report 2022,” Stanford Institute for Human-Centered AI, Stanford University, March 2022, https://aiindex.stanford.edu/wp-content/uploads/2022/03/2022-AI-Index-Report_Master.pdf ↩︎
- https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai-in-2022-and-a-half-decade-in-review ↩︎
- “2021 AI Predictions: No uncertainty here,” PwC, October 2020, https://www.pwc.com/mt/en/publications/technology/ai-predictions-2021/ai-predictions-2021-no-uncertainty-here.html ↩︎
- https://www.mckinsey.com/capabilities/quantumblack/our-insights/generative-ai-is-here-how-tools-like-chatgpt-could-change-your-business ↩︎