
Today, MLCommons® announced new results for the MLPerf® Training v6.0 benchmark suite. The two new benchmarks added in this round, and the submissions received, highlight rapid and significant changes in the AI ecosystem.
“It’s an exciting moment for the community,” said Shriya Rishab, MLPerf Training Working Group co-chair. “We’re seeing strong convergence on a set of best practices for training AI models, but at the same time there is increasing technical diversity in the underlying frameworks and systems that are being used to host and run them.”
MLPerf Training v6.0 adds two new benchmarks, emphasizing sparse computation
The MLPerf Training benchmark suite comprises full system tests that stress models, software, and hardware for a range of machine learning (ML) applications. The open-source and peer-reviewed benchmark suite provides a level playing field for competition, driving innovation, performance, and energy efficiency across the industry. The suite’s benchmark collection is curated by a panel of experts from the AI community.
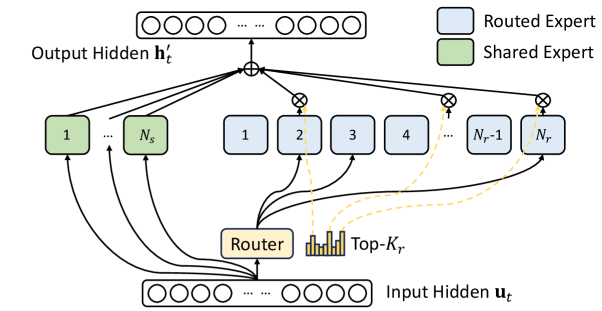
Version 6.0 adds two new benchmarks: DeepSeek V3 and GPT-OSS 20B, both highlighting the industry-wide shift to sparse computation as exemplified by a Mixture-of-Experts (MoE) architecture. Mixture-of-Experts is a model architecture that uses a smart “router” to send different tokens to specialized sub-networks (“experts”). This enables using a high-parameter-count model that is very efficient because training and inference only activate a fraction of the experts for any given token, reducing the computational cost.
DeepSeek V3 is a large-scale pretraining model, utilizing an MoE architecture. It uses 671 billion total parameters, of which 37 billion are activated per token. It provides a standardized platform for evaluating the training efficiency of a leading open-weights MoE model at production scale.
GPT-OSS 20B, also an MoE model, uses a much smaller footprint: 21 billion total parameters, of which 3.6 billion are activated per token. This allows organizations to evaluate the complex routing logic and sparse computation patterns common to MoE architecture on hardware configurations as small as a single 8-GPU node.
“Sparse computation is a dominant trend in AI right now,” said Rishab. “Over the past two years, all of the major new generative AI models have utilized a sparse computation architecture, frequently MoE. We have introduced our new DeepSeek V3 benchmark to test large-scale sparse computation training systems, and in fact it is now the largest benchmark in our suite with 671 billion parameters. It also exercises the performance of critical innovations that are now standard in the industry, including Multi-head Latent Attention (MLA) and auxiliary-loss-free load balancing.
“On the opposite end of the spectrum, we’ve introduced the GPT-OSS 20B benchmark as an entry point for organizations that may not have the resources to train the largest-scale models, but want to build advanced capabilities. We’ve carefully designed the benchmark for this scenario, including training from randomized weights to avoid the overhead of multi-gigabyte checkpoint downloads; using the same dataset as existing benchmarks in the suite such as Llama 3.1 8B; and choosing a representative sliver of end-to-end training to reduce the cost of generating benchmark results without compromising on the quality of the benchmark.
“Both of these new benchmarks saw quick uptake, drawing many results. Stakeholders clearly see the importance of performance benchmarking for MoE architectures.”
Increasing diversity of submissions highlights new paths to AI training
Version 6.0 set new records for diversity of the systems submitted. Participants in this round of the benchmark submitted 95 unique systems, utilizing thirteen different hardware accelerators, 19 different host processors and a couple of different software frameworks. 60% of the systems were multi-node.
Notably, there are more than double the number of cloud systems submitted compared to the version 5.1 results six months ago, reflecting the emerging market for hosting AI training in the cloud.
“There are more ways of getting your AI training than ever before,” said Pavan Yalamanchili, MLPerf Working Group co-chair. “Several companies now offer training systems in the cloud, complementing the on-premises systems that continue to be built out at a furious pace. And we are excited to see so many competitive submissions from a variety of on-premises and cloud providers.”
At the same time, the submissions illustrate growing technical diversity, reflecting a robust, rapidly advancing ecosystem. For example, submitters used multiple different FP4-precision recipes, reflecting the current diversity and exploration across the industry.
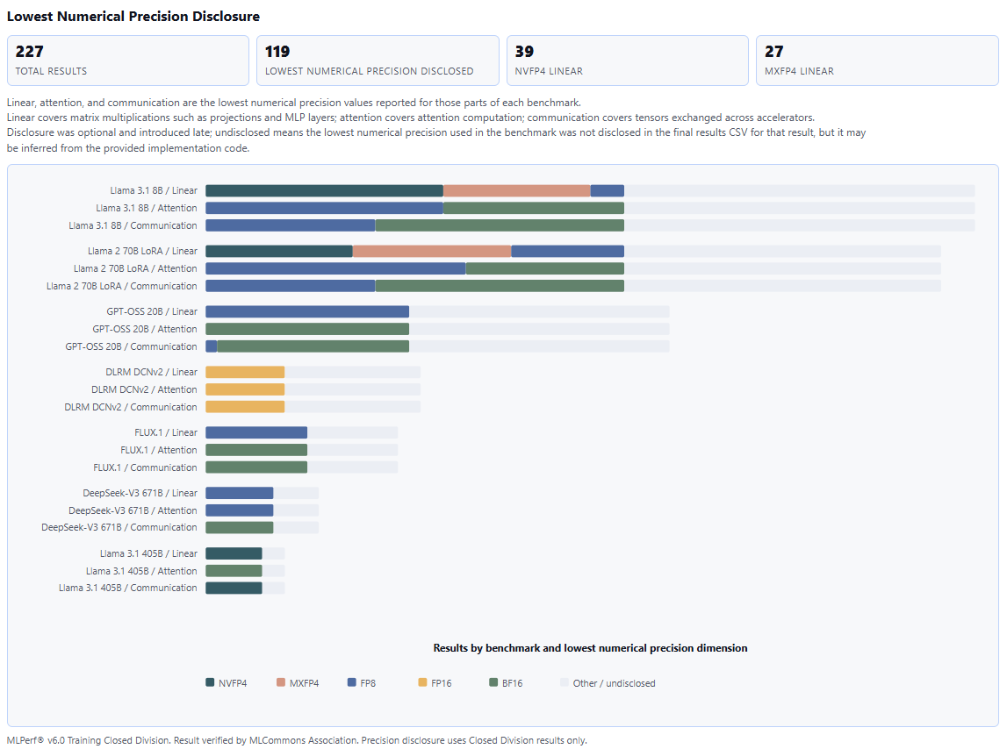
“The diversity of FP4 implementations we see in the submissions is not surprising,” said Yalamanchili. “Some implementations are more flexible than others, which allow them to be used in unique training scenarios. But here is where MLPerf’s benchmarking delivers critical insight and value: it allows stakeholders to understand which implementations deliver the best performance for their specific needs. In particular, because MLPerf benchmarks require submissions to meet an accuracy threshold, we shine a spotlight on the differences in performance that these kinds of hardware and implementation design choices can lead to.”
Record industry participation points to broad ecosystem, driven by generative AI
The MLPerf Training v6.0 round includes performance results from 24 submitting organizations: AMD, ASUSTeK, Azure, Cisco, CoreWeave, Dell, Fujitsu, GigaComputing, Google, HPE, Inventec, Krai, Lambda, MITAC, Nebius, Netweb Technologies India LTD, NVIDIA, Oracle, Quanta Cloud Technologies, SCITIX, Supermicro, tinycorp, TTA and Vultr. “We would especially like to welcome first-time MLPerf Training submitters, Inventec, Netweb Technologies India LTD, TTA and Vultr ” said David Kanter, Head of MLPerf at MLCommons.
Robust participation by a broad set of industry stakeholders strengthens the AI ecosystem as a whole and helps to ensure that the benchmark is serving the community’s needs. We invite submitters and other stakeholders to join the MLPerf Training working group and help us continue to evolve the benchmark.
View the results
Please visit the Training benchmark page to view the full results for MLPerf Training v6.0 and find additional information about the benchmarks. To learn about each submitter’s results, read the supplemental.
About ML Commons
MLCommons is the world’s leader in AI benchmarking. An open engineering consortium supported by over 125 members and affiliates, MLCommons has a proven record of bringing together academia, industry, and civil society to measure and improve AI. The foundation for MLCommons began with the MLPerf benchmarks in 2018, which rapidly scaled as a set of industry metrics to measure machine learning performance and promote transparency of machine learning techniques. Since then, MLCommons has continued using collective engineering to build the benchmarks and metrics required for better AI – ultimately helping to evaluate and improve AI technologies’ accuracy, safety, speed, and efficiency.
For additional information on MLCommons and details on becoming a member, please visit MLCommons.org or email [email protected].
Press Inquiries: contact [email protected]