
Introduction
The MLPerf® Inference v6.0 release marks a significant expansion in our coverage of the open-weight large language model (LLM) landscape. As the industry moves toward more specialized and capable open models, the benchmarks must evolve to reflect these shifts in deployment strategies and model architectures.
In this round, the Reasoning LLM task force introduces two major additions to the suite:
- GPT-OSS 120B: a new benchmark based on a popular open-source, high-capability model which excels at mathematics, scientific reasoning, and coding. It features a large-scale mixture-of-experts (MOE) architecture of 117B total parameters.
- DeepSeek-R1 interactive scenario: Building upon the existing DeepSeek-R1 benchmark, we add a low-latency-constrained interactive workload targeting real-time reasoning applications. This workload also features the first standard for speculative decoding in MLPerf.
A new benchmark with GPT-OSS 120B
GPT-OSS 120B is a popular new open-source, high-capability model, featuring a mixture-of-experts (MoE) architecture with 117B total parameters (5.1B active per token). This model natively supports configurable reasoning effort levels and is deployed across a diverse range of complex, knowledge-intensive workflows including advanced coding, competition mathematics, and graduate-level scientific logic.
Frontier models are often deployed across a wide spectrum of production workloads—from fast, routine requests to complex, multi-step problem solving. To accurately reflect this duality, we introduced a split-dataset strategy:
- Performance dataset of routine, low-effort usage tasks (e.g., summarization)
- Accuracy dataset of difficult reasoning problems across coding, scientific knowledge and math.
Across both modes, all inputs utilize the OpenAI Harmony chat format, allowing us to natively control the model’s reasoning effort (low, medium, or high) directly through system prompts.
Dataset selection for GPT-OSS
For the first time in MLPerf inference benchmark we have decided to separate performance and accuracy datasets. In all existing MLPerf Inference benchmarks, a single dataset is used for both. However, separating the two brings flexibility that allows agility in benchmark definition for this workload and also in the future. Additionally, the two tasks are different, and the separation allows the use of an optimal dataset for each task.
A key consideration in the task force deliberation has been to ensure consistency between performance and accuracy runs. This issue was resolved by adding a new compliance test that verifies accuracy while running in the performance mode.
Accuracy mode (high reasoning effort)
To ensure the benchmark sticks to a fair accuracy baseline, we curated a composite dataset requiring high reasoning effort.
- Max output length: 32,768 tokens.
- Evaluation strategy: Pass @ 1 with k repeats.
- Datasets:
- AIME 2024: Advanced mathematics problems. Metric: Exact Match.
- LiveCodeBench v6: Real-time coding tasks. Metric: Pass/Fail.
- GPQA-Diamond: Graduate-level science QA. Metric: Correct/Not Correct.
The evaluation and dataset curation was based on OpenAI’s official evaluation scripts. We created a feature branch (feat/mlperf_integration) that:
- Enabled inference on tokenized inputs (HarmonySampler), and
- Added evaluation for LiveCodeBench v6
To curate the accuracy dataset, we then collected input traces from running `gpt_oss.evals` and ran multiple times to get a reliable accuracy threshold on AIME25, LCB_V6 and GPQA_Diamond.
Accuracy targets for GPT-OSS
To qualify for submission, implementations must meet or exceed the following accuracy targets on the curated accuracy dataset:
| Dataset | Repeats per Sample | Accuracy Target | Evaluation Metric |
| AIME 2024 | 8 | 82.92% | Exact Match (MCQ) |
| GPQA-Diamond | 5 | 74.95% | Correct/Not Correct |
| LiveCodeBench v6 | 3 | 84.68% | Pass/Fail (Code Execution) |
Performance mode (low reasoning effort)
For measuring pure inference speed (tokens/second), we utilize a dataset sampled from ccdv/pubmed-summarization.
- Task: PubMed health article summarization.
- Configuration: “Low reasoning effort” via Harmony format.
- Sequence lengths: Max output length is set to 10,240 tokens.
- Metrics: Throughput and Latency.
- Mean input sequence length: 5,000 tokens
- Mean output sequence length: 1,250 tokens
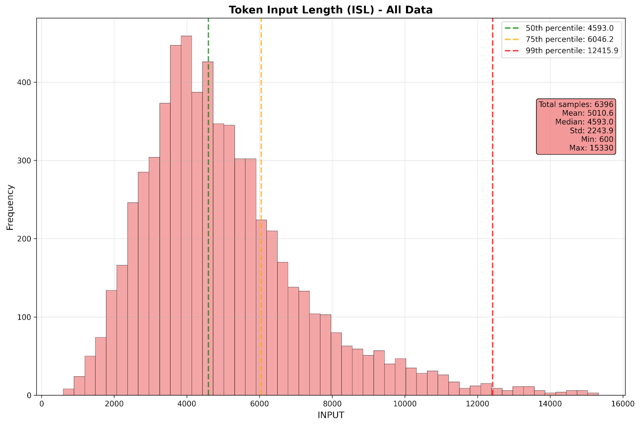
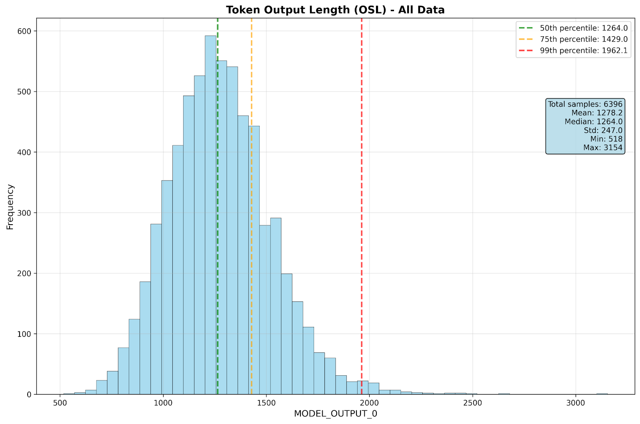
Performance metrics
The performance metrics evaluate the systems under strict latency constraints depending on the deployment scenario.
GPT-OSS constraints:
- Interactive Scenario: 99th percentile TTFT <= 2.0s; TPOT <= 15ms.
- Server Scenario: 99th percentile TTFT <= 3.0s; TPOT <= 80ms.
Accuracy metrics
For GPT-OSS, accuracy is evaluated strictly on the accuracy mode dataset. AIME 2024 is evaluated via Exact Match, LiveCodeBench v6 via Code Execution (Pass/Fail), and GPQA-Diamond via Correct/Not Correct mapping.
Compliance checks
Because this benchmark uses separate datasets for accuracy and performance evaluations, new compliance checks were introduced to ensure accuracy when running in performance modes. The tests are as follows:
- TEST07: This test verifies the accuracy of a performance run by using the GPQA dataset, one of the three accuracy datasets. Using all three datasets would be too computationally expensive, and the task force decided to use a subset for enforcing the accuracy verification.
- TEST09: This test verifies that the mean output length generated from the performance dataset is within 10% of the output length from reference implementation.
Reference implementation
The official reference implementations for the MLPerf Inference v6.0 benchmarks provide the necessary code and instructions to run the end-to-end evaluations.
- GPT-OSS 120B: GitHub link
A new workload: the DeepSeek-R1 interactive scenario
Building on the DeepSeek-R1 benchmark introduced in v5.1, we added an interactive scenario designed to represent the growing demand for low-latency responses in advanced reasoning uses cases like math, knowledge and reasoning, and complex coding tasks. The dataset (LiveCodeBench, MATH500, AIME, GPQA-Diamond, and MMLU-Pro) remains identical to the server scenario, with a minimum query count of 4,388, but the workload shifts to tighter bounded response times than server scenario.
Performance metrics
The performance metrics evaluate the systems under strict latency constraints depending on the deployment scenario.
DeepSeek-R1 Interactive Constraints & Speculative Decoding:
- New interactive scenario (Poisson arrival): 99th percentile TTFT <= 1.5s; TPOT <= 15ms.
- (Existing) server scenario (Poisson arrival): 99th percentile TTFT <= 2s, TPOT <= 80ms.
To meet the demanding latency requirements of the DeepSeek-R1 Interactive scenario, we are enabling speculative decoding for this specific workload. Implementations must use the official DeepSeek-R1 MTP (Multi-Token Prediction) Head with EAGLE-style decoding:
- Algorithm: EAGLE-style decoding with deepseek-ai/deepseek-r1 MTP head.
- Configuration: speculative-num-steps=3, speculative-eagle-topk=1.0.
- Prohibitions: Implementations cannot artificially manipulate acceptance rates. Techniques such as continued pre-training of the MTP head, quantization of the MTP head weights, or post-training adjustments (fine-tuning, RLHF) are strictly disallowed.
- See official rules here: mlperf-inference/policies
Accuracy metrics
For DeepSeek-R1 interactive, the accuracy metrics remain identical to the v5.1 server submission (exact match for math/QA and code execution for LiveCodeBench), ensuring the speculative decoding implementation does not degrade the model’s reasoning capabilities.
Reference implementation
The official reference implementations for the MLPerf Inference v6.0 benchmarks provide the necessary code and instructions to run the end-to-end evaluations.
- DeepSeek-R1: GitHub link
Conclusion
With MLPerf Inference v6.0, we continue to push the boundaries of what a standardized benchmark suite can measure. By introducing a split-dataset approach for GPT-OSS and a rigorous, latency-constrained Interactive scenario for DeepSeek-R1, we are providing the industry with the tools needed to evaluate the next generation of AI applications—from high-throughput summarization to real-time agentic reasoning.
We invite the community to explore the reference implementations and to participate in future rounds as we continue to track the rapid evolution of large language models.
For additional information on MLCommons and details on becoming a member, please visit MLCommons.org or email [email protected].