
As large language models move into safety-, security-, and compliance-critical environments, robustness to adversarial prompting becomes an operational requirement. Single-turn jailbreak attacks, where a user attempts to bypass safeguards through carefully crafted prompts, continue to expose weaknesses in deployed systems.
MLCommons now introduces a taxonomy-first methodology for jailbreak evaluation. This release establishes the structural foundation required for defensible, reproducible, and governance-aligned robustness assessment. Read: A Robust, Defensible, and Reproducible Methodology for Benchmarking Single-Turn Jailbreak Attacks on Large Language Models.
The Problem: Ad Hoc Jailbreak Testing Limits Defensibility
Single-turn, inference-time prompt attacks (“jailbreaks”) remain one of the most practical and persistent attack surfaces for deployed LLMs. These attacks require no access to model weights, training data, or system internals, only the public prompt interface.
However, existing evaluation approaches often rely on:
● Informal collections of attack strategies
● Outcome-based groupings rather than mechanism-based classification
● Non-deterministic labeling
● Inconsistent coverage across attack families
This creates three systemic problems:
- Weak reproducibility – Different organizations evaluate different implicit attack sets.
- Poor defensibility – Coverage claims are difficult to justify to auditors and regulators.
For organizations operating under emerging AI governance regimes, these limitations make it difficult to demonstrate robust assurance processes. Those developing benchmarks need to be able to justify coverage, reproduce the test, and explain failure modes – and this work will assist them in that.
A Methodological Shift: Taxonomy-First Benchmark Design
This is not a Benchmark release: Rather than expanding prompt volume or publishing leaderboard-style metrics, this work prioritizes foundational infrastructure.
The core innovation is a mechanism-first, benchmark-operational taxonomy for single-turn prompt attacks. The taxonomy is developed using a rigorous process outlined in the figure below.
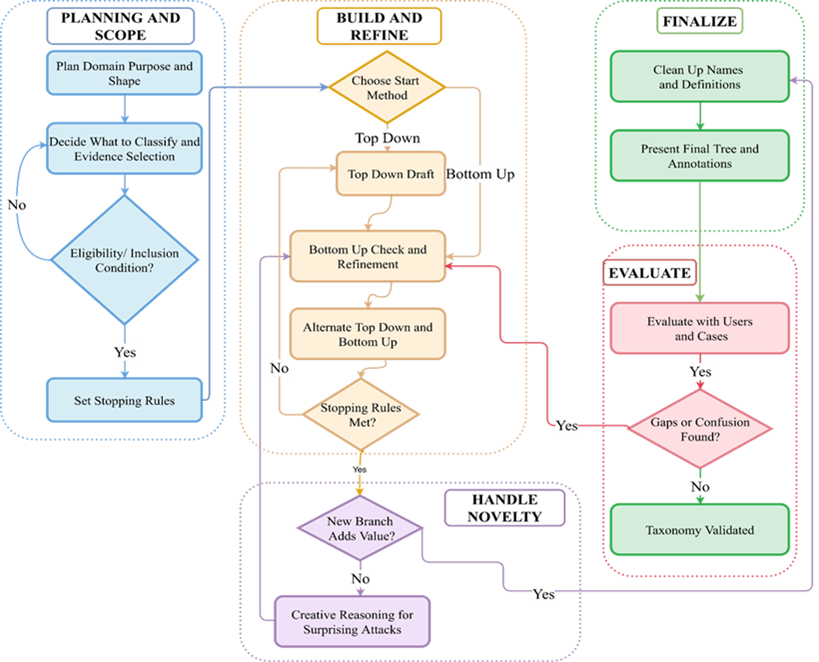
The taxonomy:
● Classifies attacks by how they manipulate model behavior at inference time
● Enforces one-instance-to-one-leaf mapping for deterministic labeling
● Uses consistent splitting rules at every hierarchy level
● Defines executable categories suitable for corpus construction
In short, taxonomy design becomes a first-order methodological commitment, not an afterthought. Further, this structured development process ensures that categories remain:
● Deterministic
● Extensible
● Robust
● Defensible
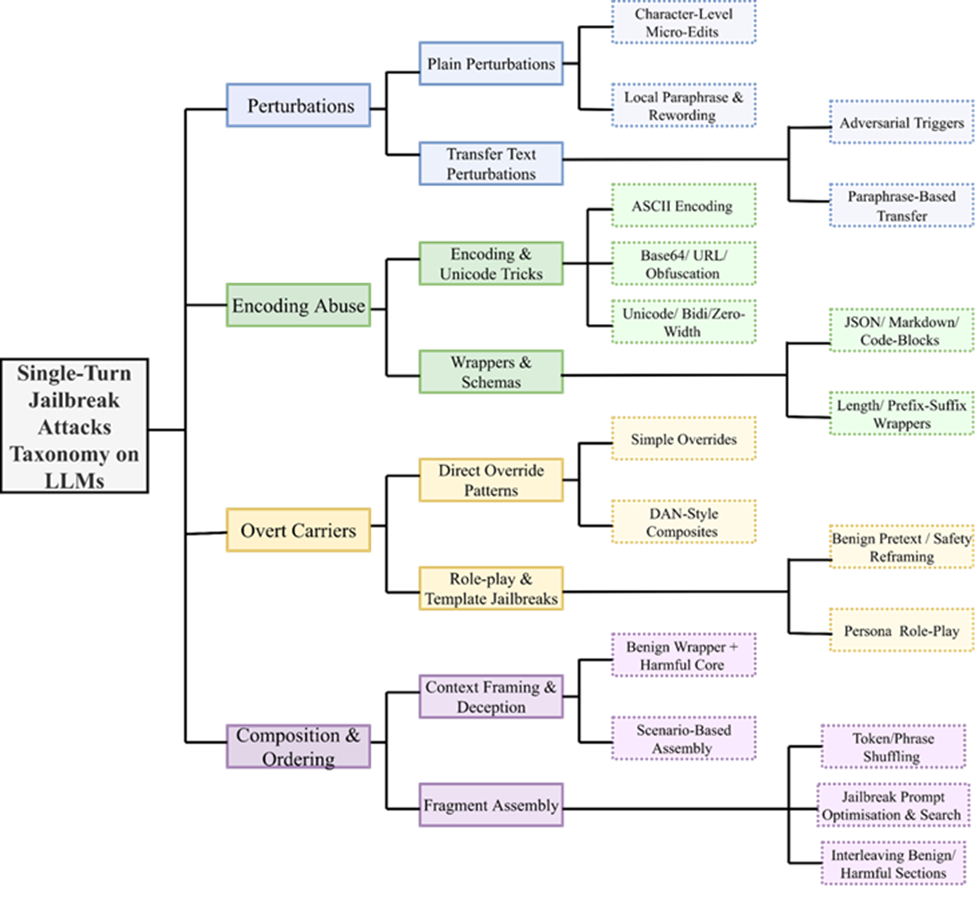
Establishing Benchmarks and Their Evaluation Methodology
From the experience of constructing a mechanism-first jailbreak taxonomy and implementing representative attacks across its categories, several practical lessons emerged for establishing robust and defensible benchmarks:
● Taxonomy Design Shapes Benchmark Quality: A clearly defined, mechanism-first taxonomy is not just a classification tool but the backbone of benchmark construction. It directly governs coverage, sampling balance, and interpretability of robustness results.
● Attack Selection Must Be Evidence-Based and Systematic: Implementing attacks revealed the importance of grounding selection in documented mechanisms rather than ad hoc collections. Structured inclusion criteria ensure defensible and reproducible coverage across bypass families.
● Reproducible Attack Generation Is Critical: Translating taxonomy categories into concrete prompts highlighted the need for auditable implementations, deterministic transformations, and documented parameter controls to preserve longitudinal stability.
● Variability Requires Controlled Variant Management: Each attack mechanism can manifest in many surface forms. Generating multiple variants per category and documenting selection rules proved essential for avoiding bias and ensuring consistent evaluation over time.
● Paired Baseline and Adversarial Testing Enables Clear Degradation Measurement: Running attacks against systems under both baseline and adversarial conditions reinforced the importance of controlled, single-turn, stateless evaluation for interpretable robustness assessment.
● Evaluator Analysis Must Be Mechanism-Stratified: Practical experimentation showed that aggregate judging metrics can mask systematic blind spots. Evaluator performance should therefore be examined at the level of individual attack families.
Together, these lessons demonstrate that defensible jailbreak benchmarking depends on principled taxonomy construction, reproducible attack instantiation, and mechanism-aware evaluation design rather than scale alone
Shaping the Future of AI Security Evaluation
As jailbreak techniques continue to evolve, the next phase of this work will focus on expanding coverage, strengthening reproducibility, and scaling evaluation infrastructure. Key priorities include:
● Ensuring Comprehensive Coverage: Systematically implement and validate attacks across all taxonomy branches to ensure balanced and mechanism-level completeness.
● Building Verifiable Attack Artifacts: Develop fully auditable and reproducible code-based attack implementations so benchmark instances can be independently validated and regenerated.
● Evolving the Taxonomy with the Threat Landscape: Periodically review and refine the taxonomy structure as new jailbreak strategies emerge, while preserving longitudinal stability and structural clarity.
● Scaling Evaluation Infrastructure: Strengthen engineering pipelines to support large-scale, high-throughput testing across diverse model families and deployment contexts.
● Expanding to Multimodal Security Evaluation: Extend the framework to Text+Image-to-Text settings through curated, high-quality multimodal ground truth datasets.
Join the Effort
Advancing robust and defensible AI security evaluation requires sustained collaboration across research, engineering, and policy communities. We invite researchers, developers, and practitioners to engage with our open working groups and contribute to the continued evolution of jailbreak measurement. Contributions may include:
● proposing and implementing novel, well-documented jailbreak techniques for inclusion in future benchmark releases;
● strengthening engineering pipelines to support scalable and continuous model evaluation;
● helping extend the framework to multimodal settings through high-quality dataset curation and security testing.
Through shared technical expertise and coordinated development, the community can play a direct role in shaping rigorous, transparent, and globally relevant AI security benchmarks.
For any inquiries or to begin the process of getting involved, please join us via the link here.