The MLCommons® Storage Working Group is excited to announce the availability of the MLPerf™ Storage Benchmark Suite. This is the first artificial intelligence/machine learning benchmark suite that measures the performance of storage for machine learning (ML) workloads. It was created through a collaboration across more than a dozen leading organizations. The MLPerf Storage Benchmark will be an effective tool for purchasing, configuring, and optimizing storage for ML applications, as well as designing next-generation systems and technologies.
Striking a Balance Between Storage and Compute
Training neural networks is both a compute and data-intensive workload that demands high-performance storage to sustain good overall system performance and availability. For many customers developing the next generation of ML models, it is a challenge to find the right balance between storage and compute resources while making sure that both are efficiently utilized. MLPerf Storage helps overcome this problem by accurately modeling the I/O patterns posed by ML workloads for various accelerator types, providing the flexibility to mix and match different storage systems with different accelerator types.
How it Works
MLPerf Storage measures the sustained performance of a storage system for MLPerf Training and HPC workloads on both PyTorch and Tensorflow without requiring the use of expensive accelerators. It instead relies on a novel and elegant emulation mechanism that captures the full realistic behavior of neural network training. The first round of MLPerf Storage includes the BERT model which pioneered transformers for language modeling and 3DUNet which performs segmentation for 3D medical images. Subsequent rounds will expand the number and variety of workloads, the variety of emulated accelerators, and other features.
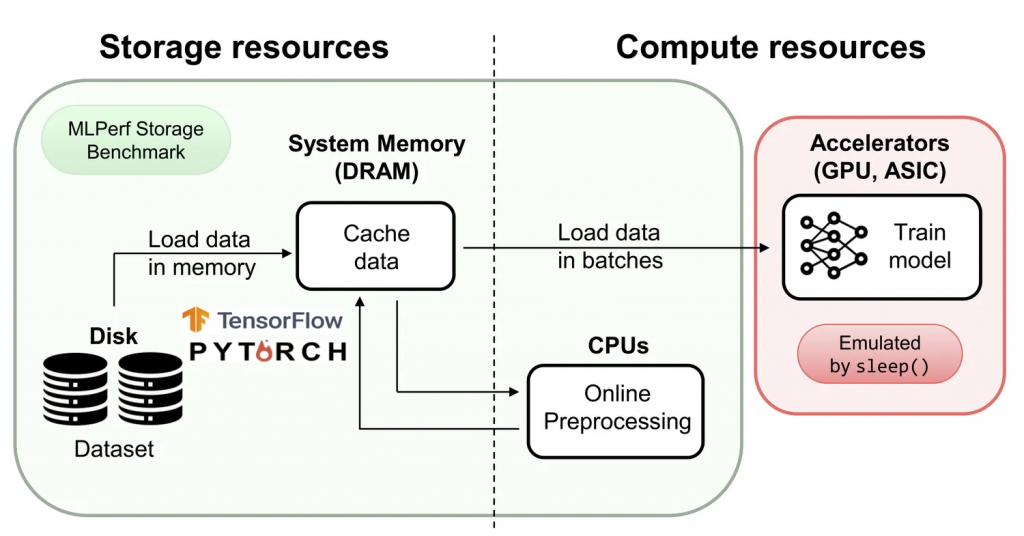
MLPerf Storage overview: Data loading and on-line pre-processing are performed using the ML frameworks, while model training is emulated.
The MLPerf Storage Benchmark Suite marks a major milestone in MLCommons’ line-up of MLPerf training benchmark suites. With the addition of MLPerf Storage, we hope to stimulate innovation in the academic and research communities to push the state-of-the-art in storage for ML, as well as providing a flexible tool for cluster designers to understand the interplay between storage and compute resources at scale. We are excited to see how the community will accelerate storage performance for some of the world’s most valuable and challenging emerging applications.
The MLPerf Storage inference benchmarks were created thanks to the contributions and leadership of our working members over the last 18 months.
MLPerf Storage Benchmark timeline
- MLPerf Storage open for submissions June 19, 2023
- All submissions are due August 4, 2023
- Benchmark competition results publish September 13, 2023
How to Get Involved
- Submit a benchmark result.
- Spread the word to companies who would be interested in submitting.
- Help us continue the development of the MLPerf Storage Benchmark by joining the working group.