MLPerf Inference: Datacenter Benchmark Suite Results

Overview
The MLPerf Inference: Datacenter benchmark suite measures how fast systems can process inputs and produce results using a trained model. Below is a short summary of the current benchmarks and metrics.
The MLPerf Inference benchmark paper provides a detailed description of the motivation and guiding principles behind the MLPerf Inference: Datacenter benchmark suite.
Results
MLCommons results are shown in an interactive table to enable you to explore the results. You can apply filters to see just the information you want and click across the top tabs to view the results visually. To see all result details, expand the columns by clicking on the “+” icon, which appears when you hover over “System Name” and subsequent columns.
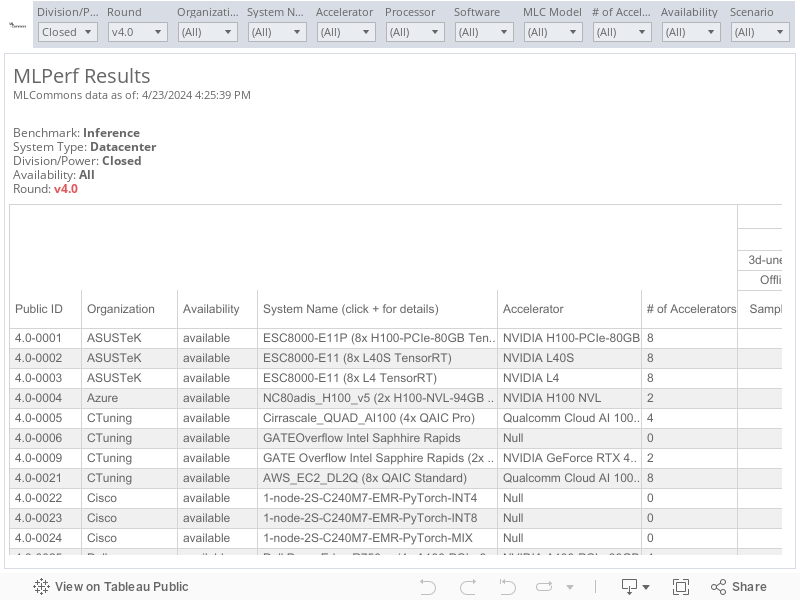
Scenarios and Metrics
To enable representative testing of a wide variety of inference platforms and use cases, MLPerf has defined four different scenarios as described below. A given scenario is evaluated by a standard load generator generating inference requests in a particular pattern and measuring a specific metric.
| Scenario | Query Generation | Duration | Samples/query | Latency Constraint | Tail Latency | Performance Metric |
|---|---|---|---|---|---|---|
| Single stream | LoadGen sends next query as soon as SUT completes the previous query | 1024 queries and 60 seconds | 1 | None | 90% | 90%-ile measured latency |
| Multiple stream (1.1 and earlier) | LoadGen sends a new query every latency constraint if the SUT has completed the prior query, otherwise the new query is dropped and is counted as one overtime query | 270,336 queries and 60 seconds | Variable, see metric | Benchmark specific | 99% | Maximum number of inferences per query supported |
| Multiple stream (2.0 and later) | Loadgen sends next query, as soon as SUT completes the previous query | 270,336 queries and 600 seconds | 8 | None | 99% | 99%-ile measured latency |
| Server | LoadGen sends new queries to the SUT according to a Poisson distribution | 270,336 queries and 60 seconds | 1 | Benchmark specific | 99% | Maximum Poisson throughput parameter supported |
| Offline |
LoadGen sends all queries to the SUT at start |
1 query and 60 seconds | At least 24,576 | None | N/A | Measured throughput |
Benchmarks
Each benchmark is defined by a Dataset and Quality Target. The following table summarizes the benchmarks in this version of the suite (the rules remain the official source of truth):
| Area | Task | Model | Dataset | QSL Size | Quality | Server latency constraint | Latest Version Available |
|---|---|---|---|---|---|---|---|
| Vision | Image classification | Resnet50-v1.5 | ImageNet (224×224) | 1024 | 99% of FP32 (76.46%) | 15 ms | v4.0 |
| Vision | Object detection | Retinanet | OpenImages (800×800) | 64 | 99% of FP32 (0.20 mAP) | 100 ms | v4.0 |
| Vision | Medical image segmentation | 3D UNET | KITS 2019 (602x512x512) | 16 | 99% of FP32 and 99.9% of FP32 (0.86330 mean DICE score) | N/A | v4.0 |
| Speech | Speech-to-text | RNNT | Librispeech dev-clean (samples < 15 seconds) | 2513 | 99% of FP32 (1 – WER, where WER=7.452253714852645%) | 1000 ms | v4.0 |
| Language | LLM – Q&A | Llama 2 70B | OPEN ORCA | 24576 | ROUGE-1 = 44.4312 ROUGE-2 = 22.0352 ROUGE-L = 28.6162 |
TTFT: 2s & TPOT: 200ms | v4.0 |
| Language | LLM – Summarization | GPT-J 6B | CNN-DailyMail News Text Summarization | 13368 | 99.9% or 99% of the original FP32 ROUGE 1 – 42.9865 ROUGE 2 – 20.1235 ROUGE L – 29.9881 | N/A | v4.0 |
| Language | Language processing | BERT-large | SQuAD v1.1 (max_seq_len=384) | 10833 | 99% of FP32 and 99.9% of FP32 (f1_score=90.874%) | 130 ms | v4.0 |
| Image | Image Generation | SDXL 1.0 | COCO-2014 | 5000 | FID ∈ (23.0108, 23.9501) CLIP ∈ (31.686, 31.813) |
20 seconds | v4.0 |
| Commerce | Recommendation | DLRM-DCNv2 | Criteo 4TB Multi-hot | 204800 | 99.9% or 99% of the original FP32 AUC metric (80.31%) | 60 ms | v4.0 |
| Commerce | Recommendation | DLRM | 1TB Click Logs | 204800 | 99% of FP32 and 99.9% of FP32 (AUC=80.25%) | 30 ms | v3.0 |
| Vision | Object detection (large) | SSD-ResNet34 | COCO (1200×1200) | 64 | 99% of FP32 (0.20 mAP) | 100 ms | v2.0 |
| Vision | Medical image segmentation | 3D UNET | BraTS 2019 (224x224x160) | 16 | 99% of FP32 and 99.9% of FP32 (0.85300 mean DICE score) | N/A | v1.1 |
| Vision | Image classification | MobileNet-v1 | ImageNet (224×224) | 1024 | 99% of FP32 (71.68%) | 10 ms | v0.5 |
| Vision | Object detection (small) | SSD-MobileNets-v1 | COCO (300×300) | 256 | 99% of FP32 (0.22 mAP) | 10 ms | v0.5 |
Each Datacenter benchmark requires the following scenarios:
| Area | Task | Required Scenarios |
|---|---|---|
| Vision | Image classification | Server, Offline |
| Vision | Object detection | Server, Offline |
| Vision | Medical image segmentation | Offline |
| Speech | Speech-to-text | Server, Offline |
| Language | Language processing | Server, Offline |
| Language | Large Language Model | Server, Offline |
| Commerce | Recommendation | Single Stream, Offline |
Divisions
MLPerf aims to encourage innovation in software as well as hardware by allowing submitters to reimplement the reference implementations. There are two Divisions that allow different levels of flexibility during reimplementation. The Closed division is intended to compare hardware platforms or software frameworks “apples-to-apples” and requires using the same model as the reference implementation. The Open division is intended to foster innovation and allows using a different model or retraining.
Availability
MLPerf divides benchmark results into Categories based on availability.
- Available systems contain only components that are available for purchase or for rent in the cloud.
- Preview systems must be submittable as Available in the next submission round.
- Research, Development, or Internal (RDI) contain experimental, in development, or internal-use hardware or software.
Submission Information
Each row in the results table is a set of results produced by a single submitter
using the same software stack and hardware platform. Each Closed division row contains the following information:

Submitter
The organization that submitted the results.

Software
The ML framework and primary ML hardware library used.

System
General system description.
Benchmark Results
Results for each benchmark as described above.

Processor and Count
The type and number of CPUs used, if CPUs perform the majority of ML compute.

Details
Link to metadata for submission.

Accelerator and Count
The type and number of accelerators used, if accelerators perform the majority of ML compute.

Code
Link to code for submission.
Each Open division row may add the following information:
Model Used
The model used to produce the results, which may or may not match the Closed Division requirement.
Notes
Arbitrary notes from submitter.
For results with power measurement, each row will add columns for
each benchmark containing the following:
System power (for Server and Offline scenarios), or
Energy per stream (for Single stream and Multiple stream scenarios)
These metrics are computed using the measured average AC power (energy) consumed by the entire system for the duration of the performance measurements of a benchmark (e.g., a single network under a single scenario); the AC power is measured at the wall.
The measured power is only valid for the accompanying benchmark. MLPerf Power is only capable of measuring and validating the full system power. Any other references to power in any description (e.g., a TDP configuration, a power supply rating) are not measured or validated by MLCommons.
Rules
MLPerf Datacenter rules are here (link).
Reference Implementations
Reference implementations for the benchmarks are here (link).
Results Usage Guidelines
MLPerf™ is a trademark of MLCommons®. If you use it and refer to MLPerf results, you must follow the results guidelines. MLCommons reserves the right to determine appropriate uses of its trademark.
