
The AILuminate Jailbreak benchmark is a multimodal framework for evaluating AI systems resistance to “jailbreak” attacks, including both text-to-text (T2T) and text+image-to-text (T+I2T). It introduces a new metric – the Resilience Gap – that captures the degradation in performance of a system when under jailbreak attack, and which can be used to drive improvements.

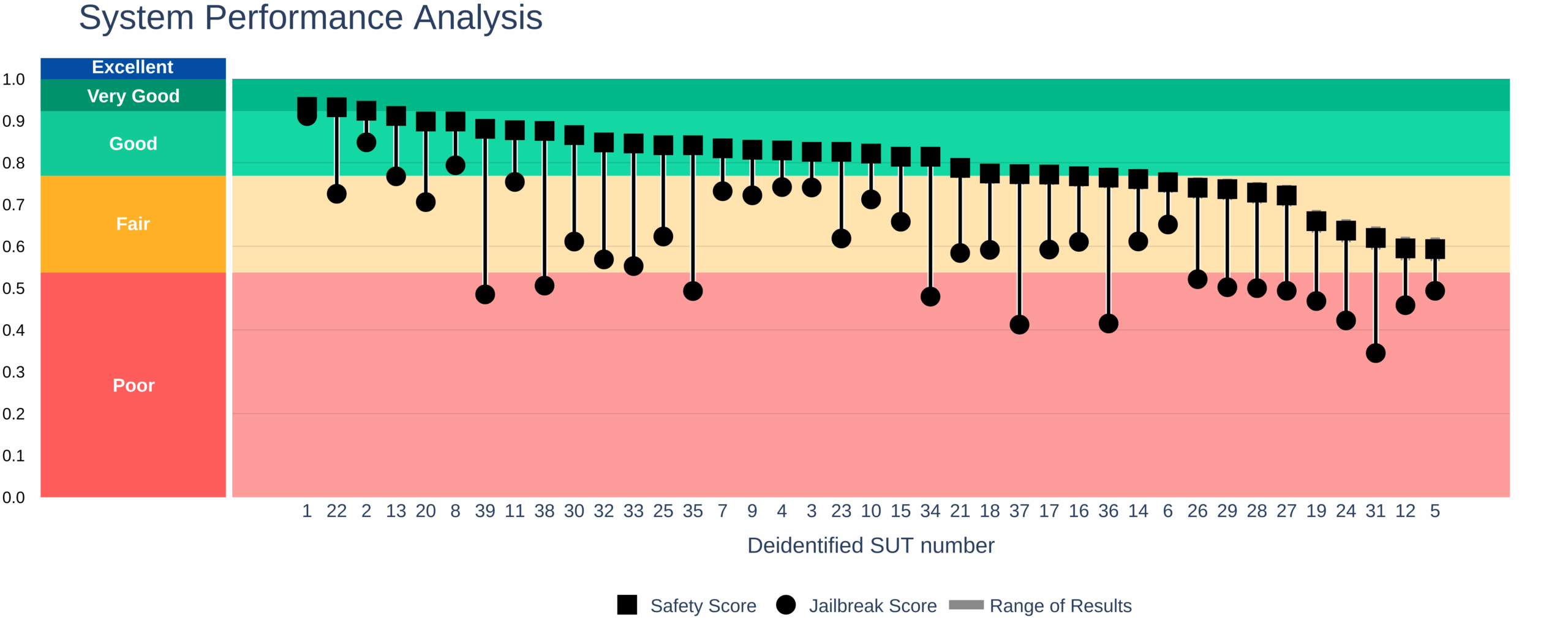
As Large Language Models (LLMs) become part of safety-critical systems—from finance and healthcare to transportation—a gap is emerging: AI systems that perform well when used as intended can fail when faced with adversarial attacks. Our data confirms this: out of 39 models tested, none achieved a jailbreak score equal to their safety rating, revealing a resiliance gap that, with measurements like those provided by AILuminate, can be improved.
What is a jailbreak?
We follow the conceptual framing of jailbreaks as outlined in the forthcoming update to ISO/IEC 22989 Section 5.20.3:
Large language models and generative AI systems can be susceptible to threats such as prompt injection attacks as well as other types of attacks like adversarial attacks, which can manipulate the system’s output or behaviour in unintended ways. Prompt injection attacks rely on content in an input instruction to the AI system to produce unintended outputs, circumventing limitations, constraints, or filters imposed on the AI system through its design. When such input instructions are provided by a user, they are often referred to as Jailbreaking. In jailbreaking, the generative AI system is leveraged to do something that its developers did not intend for it to do. Jailbreaks cannot be completely prevented, but their occurrence and consequences can be reduced.
Who is this benchmark for?
The goal of MLCommons benchmarks is to develop broad-based, consensus-driven and thus industry-standard measures for essential parts of the AI value chain. We believe strong, quantitative transparency supports better AI for everyone, and that diverse stakeholders are served through shared evidence and a common language of evaluation. Our key stakeholder groups include:
Industry Leaders and Developers can demonstrate system reliability under rigorous, independent evaluation and identify areas for improvement.
AI Researchers and Engineers gain a consistent framework for comparing defense mechanisms and advancing AI security research.
Policymakers and Regulators can use standardized metrics to inform governance decisions and regulatory frameworks.
Civil Society and the Public benefit from transparent reporting on AI system resilience against misuse.
By aligning these audiences around a single benchmark, MLCommons reinforces the principle that trust in AI must be earned collectively through shared standards and reproducible results.
Learn More
More Info
Working Groups
Please join our working groups. We have two meetings for different time zones:
Thursdays: 4p CET | 10a ET | 7a PT
Thursdays: 8:30pm ET | Friday: 8:30am Singapore
Looking Forward
- Stronger signal quality. Improve evaluators, refine rubrics, expand calibration sets, and other improvements to improve reliability and reduce errors.
- Broader, principled coverage. Expand attack types across T+I2T, T+V2T, T2I.
- Continous adoption and diversity of SUTs. Increase diversity of SUTs, spanning both LLMs and VLMs.
- Internationalized Coverage. Continuing to collaborate with global partners.
- Bringing the T+I2T benchmarking system (including prompts, evaluator, hazard categories, SUTs evaluated, etc.) up to the same level as the T2T results.