
Building on the capabilities of Croissant 1.0, MLCommons is announcing Croissant 1.1, the latest evolution of its community-built metadata format for machine learning datasets. While Croissant 1.0 established a standardized, machine-readable structure for dataset metadata, Croissant 1.1 adds machine-actionable provenance for complete data lineage, vocabulary interoperability to link metadata to domain-specific ontologies, structured usage policies for automated enforcement of consent and licensing, and enhanced data modeling for complex, multi-dimensional datasets.
It introduces new capabilities designed for the “agentic” era of AI, including machine-actionable provenance, expanded schema types, and governance tags to make datasets fully interpretable and reusable by autonomous systems.
The newer addition enables chain-of-custody checks and audits in data-centric AI systems. It adopts the W3C PROV-O model for provenance. Metadata can record how each dataset, file, or individual record was derived by linking it to source data and processing steps, and by attributing the agents (people or software) responsible.
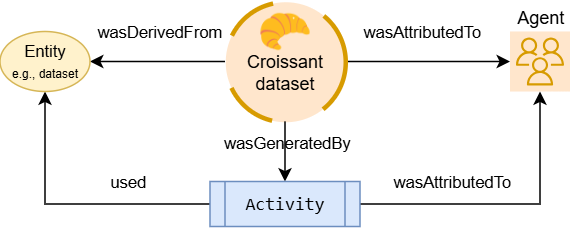
Fig: Croissant captures machine-readable data provenance
The chain-of-custody approach provides transparency to systems and auditors. They can trace a dataset through entities, activities, and agents to assess its origins and processing history. The result is a detailed audit trail embedded in the metadata, helping users verify data quality and compliance. For example, widely-used datasets like Common Crawl have adopted Croissant 1.1 metadata, demonstrating how machine-readable provenance and processing semantics can be embedded at scale.
Croissant 1.1 introduces a flexible vocabulary framework. The format supports linking metadata to external vocabularies or identifiers at multiple levels (dataset, field, or data type) so that domain-specific semantics can be reused without reinvention. For example:
- Dataset level: A dataset can reference a Wikidata or ontology ID (such as a disease or event) to classify its content, enabling cross-repository discovery.
- Field level: A column can point to a controlled vocabulary term (e.g., an environmental or phenotype concept) to clarify its meaning or cite a source.
- Data level: A field’s values can be annotated with a semantic class (for example, linking a “location” field to a geographic concept).
These conventions mean Croissant metadata can incorporate existing standards directly. Croissant was designed to be modular and extensible, so if your data already follows an ontology, you simply reference it. This interoperability is vital for portability and interoperability.
This version also strengthens support for data governance. The format can encode usage permissions and restrictions using standard policy vocabularies. For detailed consent requirements, Croissant integrates the Data Use Ontology (DUO), allowing datasets to be tagged with permitted-use categories such as “General Research Use” or “Non-Commercial Use.” These DUO tags make consent restrictions machine-discoverable.
For finer-grained control, Croissant can include W3C ODRL(Open Digital Rights Language) policies, a standard for expressing usage rules. Embedding DUO codes or ODRL terms allows agents to automatically verify whether a proposed use is permitted. Together, these capabilities position Croissant as an active enforcer of data governance within automated workflows.
Croissant 1.1 also improves how complex ML datasets are described. Fields can now represent multi-dimensional arrays, and new properties allow them to include semantic types, example values, or validation rules. Each data row can carry a clear semantic meaning, such as one field being an image and another a numeric label.
Thanks to these new capabilities, Croissant 1.1 is the ML dataset metadata standard for today’s AI landscape. It combines schema.org’s broad reach with an extensible vocabulary to produce fully machine-actionable metadata graphs that capture provenance, semantics, and governance in one place.
Self-describing metadata with embedded provenance and governance becomes crucial as AI systems move toward open models and autonomous agents. Each dataset becomes self-describing, with embedded audit trails and usage policies that support trust. The community uptake has been strong. 700K datasets now carry Croissant metadata, and primary tools and frameworks (such as TensorFlow and PyTorch for machine learning, as well as Dataverse and CKAN for data publishing) already load Croissant datasets natively. Major dataset repositories such as Hugging Face, Kaggle, and OpenML embed Croissant metadata. There is also growing community interest in applying similar provenance standards to service-generated dataset collections provided by data companies such as HumanSignal and CommonCrawl.
We encourage dataset creators to adopt Croissant 1.1 to make their data easier to find and use. Rich, interoperable metadata embedded in every dataset helps create an AI ecosystem where agents can autonomously discover and use data while fully respecting provenance, privacy, and permissions.