
The MLCommonsⓇ MLPerfⓇ Inference benchmark suite is an industry standard for measuring the performance of machine learning (ML) and artificial intelligence (AI) workloads from diverse domains including vision, speech, and natural language processing. For each of these domains, the suite includes a carefully selected set of workloads that represents the state of the art in the industry across different application segments. These benchmarks not only provide key information to consumers for making application deployment and budget decisions but also enable vendors to deliver critical workload optimizations within certain practical constraints to their customers.
From its launch, speech has been a foundational category of the MLPerf Inference suite. In the years since, voice-enabled devices and applications have proliferated throughout both consumer and commercial sectors. As the accuracy and features of speech models continue to improve, benchmarks should evolve to reflect state-of-the-art capabilities. With this goal in mind, the MLPerf Inference working group formed a special task force in early 2025 to research and develop a new speech-to-text benchmark to replace the retired RNN-T model.
Introducing Whisper-Large-V3 in MLPerf Inference v5.1
Speech-to-text was represented at the launch of MLPerf Inference by RNN-T, an early Automated Speech Recognition (ASR) model utilizing a recurrent neural network (RNN). For the MLPerf Inference v5.1 round, the Inference working group decided to revisit speech-to-text by launching a task force to define and develop a new benchmark using a state-of-the-art ASR model.
The task force examined several potential candidates including DeepSpeech and several variants of Whisper (Large-V3, Large-V3-Turbo, and Medium). After carefully reviewing the candidates, Whisper-Large-V3 (“Whisper”) was selected for this benchmark. The choice of Whisper was determined by several factors:
- High Accuracy: When evaluating models for the ASR task, accurate transcription was among the highest priorities. Whisper demonstrated the top accuracy among the candidates across a variety of datasets. Notably, Whisper reduced the word error rate (WER) of the prior MLPerf ASR model (RNN-T) by over 72% despite containing more challenging audio samples.
- Versatility: Whisper demonstrates qualities which make it particularly adaptable to real-world ASR. Whisper was trained on a breadth of multi-lingual audio sources, including challenging audio conditions such as environmental noise and accents. As a result, Whisper performs well across a range of languages and domains without need for additional fine-tuning.
- Model Architecture: Whisper is a transformer-based encoder-decoder model with 1.55B parameters. The architecture includes a sophisticated attention mechanism optimized for speech recognition using 128 mel frequency bins (that is, bins that are perceptually evenly spaced) for its spectrogram input. This is an increase from the previous 80 in Whisper-Large-V2, contributing to its improved accuracy.
- Open-Source Availability: For an open benchmark consortium, model licenses must be flexible enough to offer unlimited access by participating submitters, and ideally, to the press and public. Whisper’s weights and public code are released under the MIT license which satisfies these goals. Further, the task force’s reference code is released under the Apache 2.0 license along with the full MLPerf Inference reference suite.
- Community interests: While assessing available ASR models, the task force surveyed HuggingFace leaderboards as a proxy for community engagement. At the time of this writing, Whisper leads in both weekly downloads and developer sentiment (“likes”). This along with the prominence of Whisper variants in research citations and public rankings strongly indicate that Whisper is of broad interest to the community.
Choosing a task and a dataset for Whisper
The MLPerf benchmark suite seeks to reflect the diversity of tasks, models, and model complexity used in real-world ML deployments. While several speech-based tasks such as speech translation, language identification, and voice activity detection were identified, the ASR task was quickly selected due to its breadth of industry applications at datacenter-scale.
Once the task was identified, a selection of over 50 available audio datasets from HuggingFace were examined. This initial set was filtered to ensure predictable behavior and high potential accuracy using four criteria: (1) licensed for commercial use, (2) individual language partitions, (3) audio source documentation, and (4) available train/dev splits. The task force then surveyed HuggingFace metrics such as weekly downloads and developer sentiment to gauge community interest. The final dataset candidates were Common Voice, VoxPopuli, People’s Speech, and LibriSpeech. LibriSpeech was finally selected due to its longevity, industry popularity as an accuracy benchmark, and continuity with MLPerf’s prior RNN-T benchmark. Specifically, the LibriSpeech “dev-clean” and “dev-other” data splits were combined (“dev-all”) to ensure a range of audio quality was represented.
Once the Whisper model was selected, additional preprocessing steps were taken to enhance benchmark efficiency. Whisper has a fixed receptive window of 30 seconds, which could not be augmented to process multiple clips at runtime without substantial loss to accuracy and consistency. As a result, the original LibriSpeech clips were reconstructed into their extended source audio form and resampled using a controlled preprocessing method to approach but not exceed 30s.
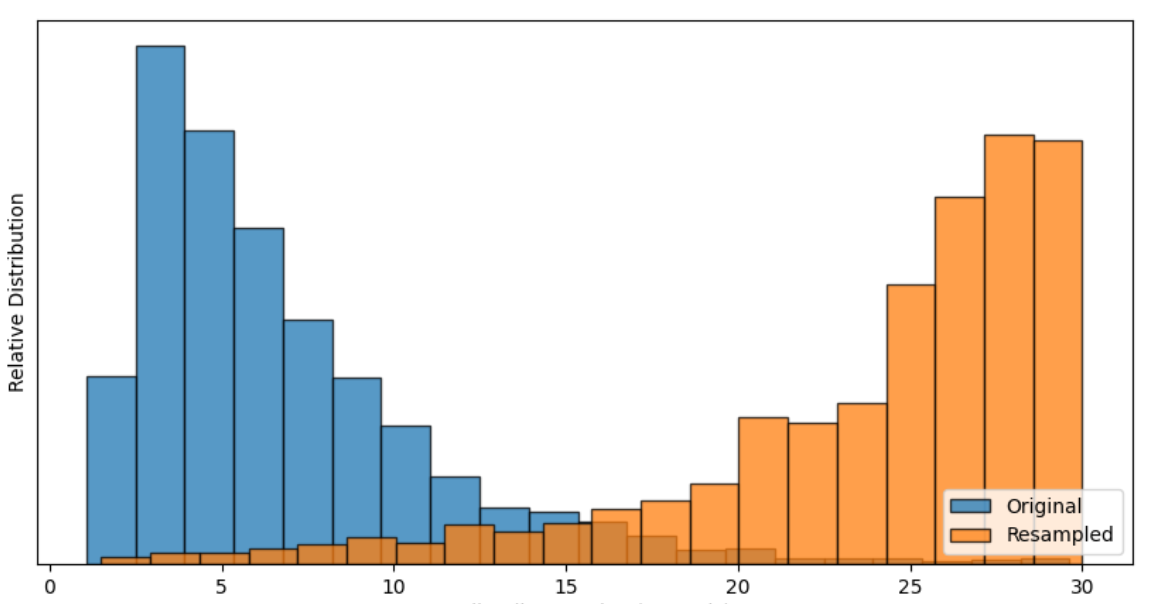
Figure 1: Audio clip length distributions for the original and resampled LibriSpeech dev-all dataset.
Defining accuracy metrics for Whisper
For automated speech recognition models, two metrics are most often used to evaluate model quality:
- Word Error Rate (WER): The relative number of transcription errors when compared to the original spoken words.
- Word Accuracy (Acc): The measure of correctly transcribed words compared to the original spoken words.
The task force carefully evaluated methods for normalizing the selected LibriSpeech dataset text, calculating the measured WER, and maintaining high model accuracy.
While researching dataset options, it was found that slight linguistic differences such as capitalization, punctuation, abbreviations, and regional spelling variations significantly impacted the measured accuracy of ASR models like Whisper. For instance, when calculating WER, transcribing “Dr.” versus “doctor” results in a measured error and “$5” versus “five dollars” results in two. Text normalization is a standard method to control such expected text variations. The following normalizations are used for this benchmark, improving measured accuracy by 1.78%:
- Text strings are reduced to lower-case and limited to alphabetic characters only. All punctuation is removed.
- OpenAI’s EnglishTextNormalizer is used to control for regional spelling differences and word contractions.
- Compound words are split in cases where doing so matches the reference text (ex. “bookshelf” will match “book shelf”).
After normalization is applied to both the ASR model output (the hypothesis) and the dataset transcript (the reference), the WER is calculated by the minimum number of word-level edits (substitutions, deletions, and insertions) required to transform the hypothesis into the reference. This is effectively a word-level version of Levenshtein distance.

Figure 2: Formulas for calculating ASR Word Error Rate (WER) and Word Accuracy (Acc).
Using the LibriSpeech dataset, data preprocessing, and text normalization methods outlined above, the Whisper reference implementation achieved a Word Accuracy of 97.9329%. The task force carefully considered how to maintain this high standard given the potential accuracy and performance trade-offs faced when quantizing and optimizing the model. As a result, submissions must achieve a measured accuracy no lower than 99% of the reference model accuracy (using the Bfloat16 numeric format) while adhering to all other MLPerf standards.
Measuring performance of Whisper
During inference, Whisper takes time-series audio data as input along with a set of prompt tokens representing the desired task, language, and other model configurations. The model generates output tokens representing the audio content.
For Whisper, this process can be divided into a prompt phase and a generation phase. In the prompt phase, the audio clip is padded to 30 seconds and processed by the encoder to generate audio features. The decoder then processes both these audio features and the text prompt to produce the first output token. In the generation phase, the decoder generates subsequent tokens autoregressively, using the audio features and past context. The encoder is not used during this stage.
The metric used for measuring Whisper performance is tokens per second (tokens/s). The resulting throughput measurement quantifies the generation speed of the output tokens and resulting text. Compared to other metrics like real-time factor (RTF), tokens/s aligns well with performance metrics for other transformer-based models.
Conclusion
In this post, we described the complexities involved in choosing the model, task, dataset, accuracy, and performance metrics of a contemporary ASR benchmark. We believe the design choices of this benchmark objectively address most of the critical deployment decisions faced by practitioners while delivering important performance insights to customers.
Details of the MLPerf Inference Whisper benchmark and reference implementation can be found here.
Given the overwhelming interests from vendors, as demonstrated by the number of submissions, we hope to continue improving the benchmark in future iterations, accounting for the different application domains relevant to ASR.