Benchmark Suite Results
MLPerf Inference: Tiny
The MLPerf Inference: Tiny benchmark suite measures how fast systems can process inputs and produce results using a trained model. Below is a short summary of the current benchmarks and metrics. Please see the MLPerf Inference benchmark paper for a detailed description of the motivation and guiding principles behind the benchmark suite.
Results
The MLPerf Inference: Tiny benchmark suite measures how fast systems can process inputs and produce results using a trained model. Below is a short summary of the current benchmarks and metrics. Please see the MLPerf Inference benchmark paper for a detailed description of the motivation and guiding principles behind the benchmark suite.
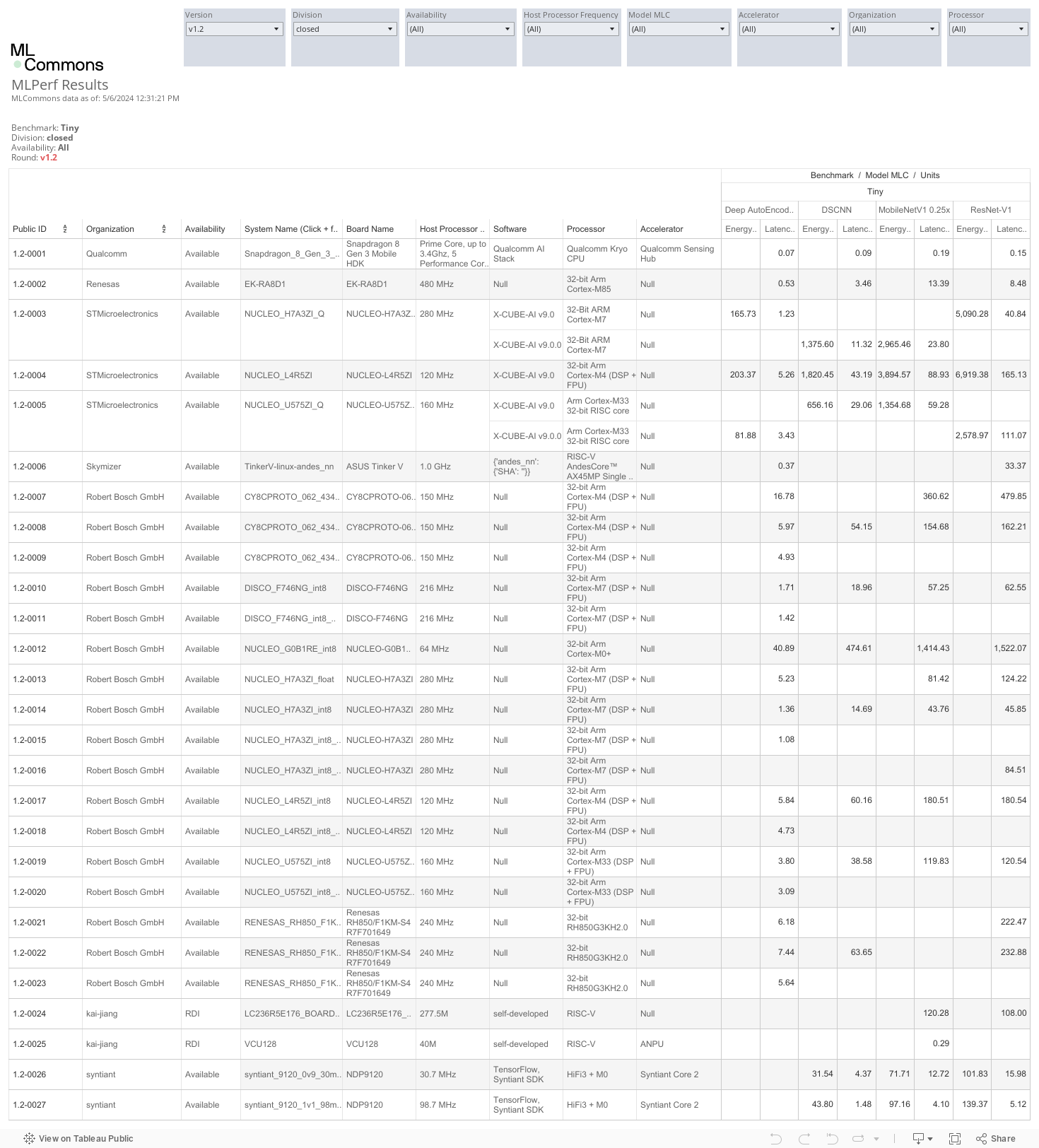
Benchmarks
Each benchmark is defined by a Dataset and Quality Target. The following table summarizes the benchmarks in this version of the suite (the rules remain the official source of truth):
| Task | Dataset | Model | Mode | Quality | Latest Version Available |
|---|---|---|---|---|---|
| Image classification | CIFAR-10 | Resnet | Single-stream | 85% (Top 1) | v1.3 |
| Person Detection (visual wakeword) | COCO | MobileNet | Single-stream | 80% (Top-1) | v1.3 |
| Keyword Spotting | Speech Commands | DS-CNN | Single-stream, Offline | 90% (Top 1) | v1.3 |
| Anomaly Detection | ADMOS Toy Car | Dense | Single-stream | 0.85 (AUC) | v1.3 |
| Streaming Wakeword | Custom (Speech Commands + MUSAN) | 1D DS-CNN | Streaming | ≤ 8 False Positive, ≤ 8 False Negative | v1.3 |
All MLPerf Tiny benchmarks are single stream, meaning they measure the latency of a single inference. The benchmarks also measure the model quality, which is either accuracy or AUC depending on the benchmark. MLPerf Tiny also enables optional energy benchmarking.
Divisions
MLPerf aims to encourage innovation in software as well as hardware by allowing submitters to reimplement the reference implementations. There are two Divisions that allow different levels of flexibility during reimplementation:
- The Closed division is intended to compare hardware platforms or software frameworks “apples-to-apples” and requires using the same model as the reference implementation.
- The Open division is intended to foster innovation and allows using a different model or retraining.
Availability
MLPerf divides benchmark results into Categories based on availability.
- Available systems contain only components that are available for purchase or for rent in the cloud.
- Preview systems must be submittable as Available in the next submission round.
- Research, Development, or Internal (RDI) contain experimental, in development, or internal-use hardware or software.
Submission Information
Each row in the results table is a set of results produced by a single submitter using the same software stack and hardware platform. Each Closed division row contains the following information:
Open Divisions
You may add the following rows:
Model Used
The model used to produce the results, which may or may not match the Closed Division requirement.
Notes
Arbitrary notes from submitter.
Power Measurements
Each row will add columns for each benchmark containing the following:
System Power
for Server and Offline scenarios, or…
Energy Per Stream
for Single stream and Multiple stream scenarios