AI benchmark for personal computers
MLPerf Client
MLPerf Client is a benchmark developed collaboratively at MLCommons to evaluate the performance of large language models (LLMs) and other AI workloads on personal computers–from laptops and desktops to workstations. By simulating real-world AI tasks it provides clear metrics for understanding how well systems handle generative AI workloads. The MLPerf Client working group intends for this benchmark to drive innovation and foster competition, ensuring that PCs can meet the challenges of the AI-powered future.
The large language model tests
The LLM tests in MLPerf Client v1.5 make use of several different language models. Large language models are one of the most exciting forms of generative AI available today. LLMs are capable of performing a wide range of tasks based on natural-language interactions. The working group chose to focus its efforts on LLMs because there are many promising use cases for running LLMs locally on client systems, from chat interactions to AI agents, personal information management, and more.
The benchmark includes multiple tasks that vary the lengths of the input prompts and output responses to simulate different types of language model use.
| Tasks | Model | Datasets | Mode | Quality |
| Code analysis Content generationCreative writingSummarization, lightSummarization, moderateSummarization, intermediate*Summarization, substantial* | Llama 3.1 8B Instruct Phi 3.5 Mini Instruct Llama 2 7B Chat* Phi 4 Reasoning 14B* | OpenOrca, GovReport, MLPerf Client source code | Single stream | MMLU score |
* Extended components
The tasks and models marked as extended or experimental are not part of the base benchmark. They are included as optional extras that can stress a system in different ways, and they may not be fully optimized on all target systems. Users may run these components in order to see how systems handle these workloads. Please note that these AI LLM workloads tend to require a relatively large amount of available memory, so the tests–and the experimental ones in particular–may not run successfully on all client-class systems.
For more information on how the benchmark works, please see the Q&A section below.
System requirements and acceleration support
Supported hardware
- AMD Radeon RX 7000 or 9000 series GPUs with 8GB or more VRAM (16GB for extended prompts)
- AMD Ryzen AI 9 series processors:
- 16GB or more system memory for GPU-only configs
- 32GB or more system memory recommended for hybrid configs
- Intel Arc B series GPUs with 10GB or more VRAM
- Intel Core Ultra Series 2 processors (Lunar Lake, Arrow Lake) with 16GB or more system memory (32GB for extended workloads)
- NVIDIA GeForce RTX 2000 series or newer GPUs with 8GB or more VRAM (16GB for extended prompts)
- Qualcomm Snapdragon X Elite platforms with 32GB or more system memory
- Apple iPads with M2-series or newer processors and 16GB of RAM
- Apple Macs with M-series processors and 16GB or more system memory
Other requirements
- Windows 11 x86-64 or Arm, macOS Tahoe 26, iPadOS 26, Ubuntu Linux 24.04 – latest updates recommended
- On Windows systems, the Microsoft Visual C++ Redistributable must be installed
- 200GB free space required on the drive from which benchmark will run
- 400GB free space recommended for running all models
- We recommend installing the latest drivers for your system
- For AMD NPUs, please use NPU driver version 32.0.203.280 or newer
- For AMD GPUs, please use GPU driver version 32.0.21025.10016 or newer from here
- For Intel NPUs, please use NPU driver version 32.0.100.4297 or newer from here
- For Intel GPUs, please use GPU driver version 32.0.101.8136 or newer from here
- For NVIDIA GPUs, please use driver version 577.00 or newer from here
- For Qualcomm NPUs, please use NPU driver version 30.0.140.1000 or newer from here
What’s new in MLPerf Client v1.5
MLPerf Client v1.5 has a host of new features and capabilities, including:
- Acceleration updates
- Support for Windows ML
- Runtime updates from IHVs
- GUI updates
- Various tweaks for usability and legibility
- GUI moves out of beta
- An iPad app
- GUI only
- A Linux version
- CLI only, experimental
- MLPerf Power/energy measurements
- An experimental addition
- Optional CLI tools and documentation
- Works in conjunction with MLPerf Power and SPEC PTDaemon
- Various improvements to the benchmark organization
- Introduction of the “extended” category for non-base, non-experimental benchmark components
- The Llama 2 7B Chat model moves from base to extended
- Some components move from experimental to extended:
- 4K and 8K prompts
- Phi 4 14B Reasoning model
- Moving out of experimental:
- Windows ML support
- Llama.cpp on Windows and Mac
Downloading the benchmark
The latest release of MLPerf Client can be downloaded from the GitHub release page. The end-user license agreed is included in the download archive file.
The iPad version is available for download via Apple’s App Store.
The public GitHub repository also contains the source code for MLPerf Client for those who might wish to inspect or modify it.
More information about how to run the benchmark is provided in the Q&A section below.
Known issues
In the GUI version of the application, on AMD-based systems, the following configs may crash:
- ORT GenAI GPU DirectML
- ORT GenAI Ryzen AI NPU-GPU
This crash is the result of an enumeration issue in the application where these configs conflict with Windows ML.
To work around this issue, we have released a build of the GUI application for Windows x64 without Windows ML support. Users of AMD systems may use this version of the benchmark to test the two ORT GenAI-based paths noted above. Please see the download options on the release page.
Where to go for support
For help with problems, to request a feature, or simply to ask a question, please fill out this form. The working group will review and respond as needed.
Common questions and answers
Which elements of the benchmark comprise the official set of tests?
Here is an overview of the prompts and models in this release of MLPerf Client.
Models for v1.5 include:
| Model | Type |
| Llama 3.1 8B Instruct | Base |
| Phi 3.5 Mini Instruct | Base |
| Phi 4 Reasoning 14B | Extended |
| Llama 2 7B Chat | Extended |
Prompt categories for v1.5:
| Prompt category | Type | Contributes to overall score? |
| Code analysis | Base | Yes |
| Content generation | Base | Yes |
| Creative writing | Base | Yes |
| Summarization, light | Base | Yes |
| Summarization, moderate | Base | Yes |
| Summarization, intermediate | Extended | No |
| Summarization, substantial | Extended | No |
Why are some portions of the benchmark marked as “extended” or “experimental?”
MLPerf Client benchmark typically components fall into one of three categories:
Base – These elements form the core of the benchmark. They are a required part of the benchmark and are the only components that can contribute to an official, “tested by MLCommons” MLPerf Client benchmark score. Base components will run on the majority of client systems.
Extended –Oftentimes, extended components–like long prompts or large models–may not run on all client class systems due to memory or compute capacity requirements. Having these components available allows MLPerf Client to push the limits of even more capable systems. Extended acceleration paths and models are subject to the same accuracy requirements as base components.
Experimental – Including experimental elements in MLPerf Client allows us to incorporate new and potentially interesting developments in AI sooner than we could otherwise. They ship with the benchmark, but the working group has not yet decided to incorporate them into the base or extended set of tests and configs, typically due to limited support or because they were a late addition during development.
Any results from extended or experimental components will be clearly marked as such when the benchmark outputs them. We would ask end users to note the extended or experimental nature of any of these results they share or publish.
Which parts of MLPerf Client are extended components?
The following elements of MLPerf Client v1.5 are considered extended components:
- Longer 4K and 8K prompts – Some configs are included that request the summarization of longer passages of text, with maximum prompt sizes of about 4K and 8K characters. These configs may surpass the limits of some client systems, but those with capable enough hardware can use these prompts to see how their computers handle them.
- The Phi 4 Reasoning 14B-parameter model – Phi 4 Reasoning 14B is a relatively new model with reasoning capabilities, and it’s almost double the size by parameter count of the other language models in this version of MLPerf Client. Like the long-context prompts, this model may not run on some systems due to its steep memory and computational requirements.
- The Llama 2 7B Chat model – Because it’s an older model, Llama 2 7B Chat has moved out of the base set of tests into the extended category but remains available for those who wish to test and compare to prior versions of MLPerf Client.
Because extended components are not part of the base benchmark, they are limited in some ways in how they contribute to reported scores. For instance, 4K and 8K prompts are reported separately and do not contribute to the overall score calculated across prompt categories for each model.
Which parts of MLPerf Client are experimental?
The following components are considered experimental:
- The Linux version of the benchmark – The CLI-only Linux version is a new addition to MLPerf Client v1.5.
- The power efficiency testing tools – These new, CLI-based tools work in conjunction with MLPerf Power to allow users to characterize the energy efficiency of various systems while running the MLPerf Client workloads.
We welcome feedback on these brand-new capabilities in MLPerf Client and look forward to refining them going forward.
What do the performance metrics mean?
The LLM tests produce results in terms of two key metrics. Both metrics characterize important aspects of the user experience.
Time to first token (TTFT): This the wait time in seconds before the system produces the first token in response to each prompt. In LLM interactions, the wait for the first output token is typically the longest one in the ensuing response. Following widespread industry practice, we have chosen to report this result separately. For TTFT, lower numbers–and thus lower wait times–are better.
Tokens per second (TPS): This is the average rate to produce all of the rest of the tokens in the response, excluding the first one. For TPS, higher output rates are better.
In a chat-style LLM usage, TTFT is the time you wait until the first character of the response appears, and tokens/s is the rate at which the rest of the response appears. The latency for a complete response is TTFT + TPS * (# of tokens in the response).
What are the different task categories in the benchmark?
Here’s a look at the token lengths for the various categories of work included in the benchmark:
| Category | Approximate input tokens | Approximate expected output tokens |
| Content generation | 128 | 256 |
| Creative writing | 512 | 512 |
| Summarization, light | 1024 | 128 |
| Summarization, moderate | 1566 | 256 |
| Code analysis | 2059 | 128 |
| Summarization, intermediate* (~4K) | 3906 | 128 |
| Summarization, substantial* (~8K) | 7631 | 128 |
* Extended prompts
You may find that hardware and software solutions vary in their performance across the categories, with larger context lengths being more computationally expensive.
All of the input prompts used in the base categories come from the OpenOrca data set with the exception of the code-analysis prompt set, which we created from our own open-source code repository. The extended categories contain prompts from the Government Report data set.
What is a token?
The fundamental unit of length for inputs and outputs in an LLM is a token. A token is a component part of language that the machine-learning model uses to understand syntax. Tokens can be words, parts of words, or punctuation marks. For instance, complex words like “everyone” could be made up of two tokens, one for “every” and another for “one.”
An example of tokenization. Each colored region represents a token.
As a rule of thumb, 100 tokens would typically translate into about 75 English words. This tokenizer tool will give you a sense of how words and phrases are broken down into tokens. Note that tokenization methods and token counts can vary slightly from one model to the next.
How is the benchmark optimized for client systems, and how do you ensure quality results?
Many generative AI models are too large to run in their native form on client systems, so developers often modify them to make them fit in the memory and computational footprints required. This footprint reduction is typically achieved through model quantization–by changing the datatype used for model weights from the original 16- or 32-bit floating-point format (fp16 or fp32) to something more compact. For LLMs in client systems, the 4-bit integer format (int4) is a popular choice. Thus, in MLPerf Client v1.5, the weights in the language models have been quantized to the int4 format. This change allows the models to fit and function well on a broad range of client devices, from laptops to desktops and workstations.
That said, reducing the precision of the weights can also come with a drawback: a reduction in the quality of the AI model’s outputs. Other model optimizations can also impact quality. To ensure that a model’s functionality hasn’t been too compromised by optimization, the MLPerf Client working group chose to impose an accuracy test requirement based on the MMLU dataset. Each accelerated execution path and model included in the benchmark must achieve a passing score on an accuracy test composed of the prompts in the MMLU corpus.
For MLPerf Client v1.0 and v1.5, the accuracy thresholds are as follows:
| Model | MMLU accuracy threshold |
|---|---|
| Llama 2 7B Chat | 43 |
| Llama 3.1 8B Instruct | 52 |
| Phi 3.5 Mini Instruct | 59 |
| Phi 4 Reasoning 14B | 70 |
The accuracy test is not part of the standard MLPerf Client performance benchmark run because accuracy testing can take quite some time. Instead, the accuracy test is run offline by working group participants in order for an acceleration path to qualify for inclusion in the benchmark release. All of the supported frameworks and models have been verified by MLC to achieve the required accuracy levels.
How does one run the CLI version of benchmark?
On Windows 11, the benchmark requires the installation of the Microsoft Visual C++ Redistributable, which is available for download here. Please install this package before attempting to run MLPerf Client.
The MLPerf Client benchmark is distributed as a Zip file. Once you’ve downloaded the Zip archive, extract it to a folder on your local drive. Inside the folder you should see a few files, including the MLPerf Client executable and several directories containing JSON config files for specific brands of hardware.
To run MLPerf Client, open a command line instance in the directory where you’ve unzipped the files. In Windows 11 Explorer, if you are viewing the unzipped files, you can right-click in the Explorer window and choose “Open in Terminal” to start a PowerShell session in the appropriate folder.
The JSON config files specify the acceleration paths and configuration options recommended by each of the participating hardware vendors.
To run the benchmark, you need to call the benchmark executable while using the -c flag and specify
ing which config file to use.
The commands in question are:
mlperf-windows.exe -c <\path\to\config-filename>.json
So, for instance, you could run Llama 3.1 8B Instruct via the NVIDIA ONNX Runtime DirectML path by typing:
mlperf-windows.exe -c .\Llama3.1\NVIDIA_ORTGenAI-DML_GPU.json
Here’s how that interaction should look:
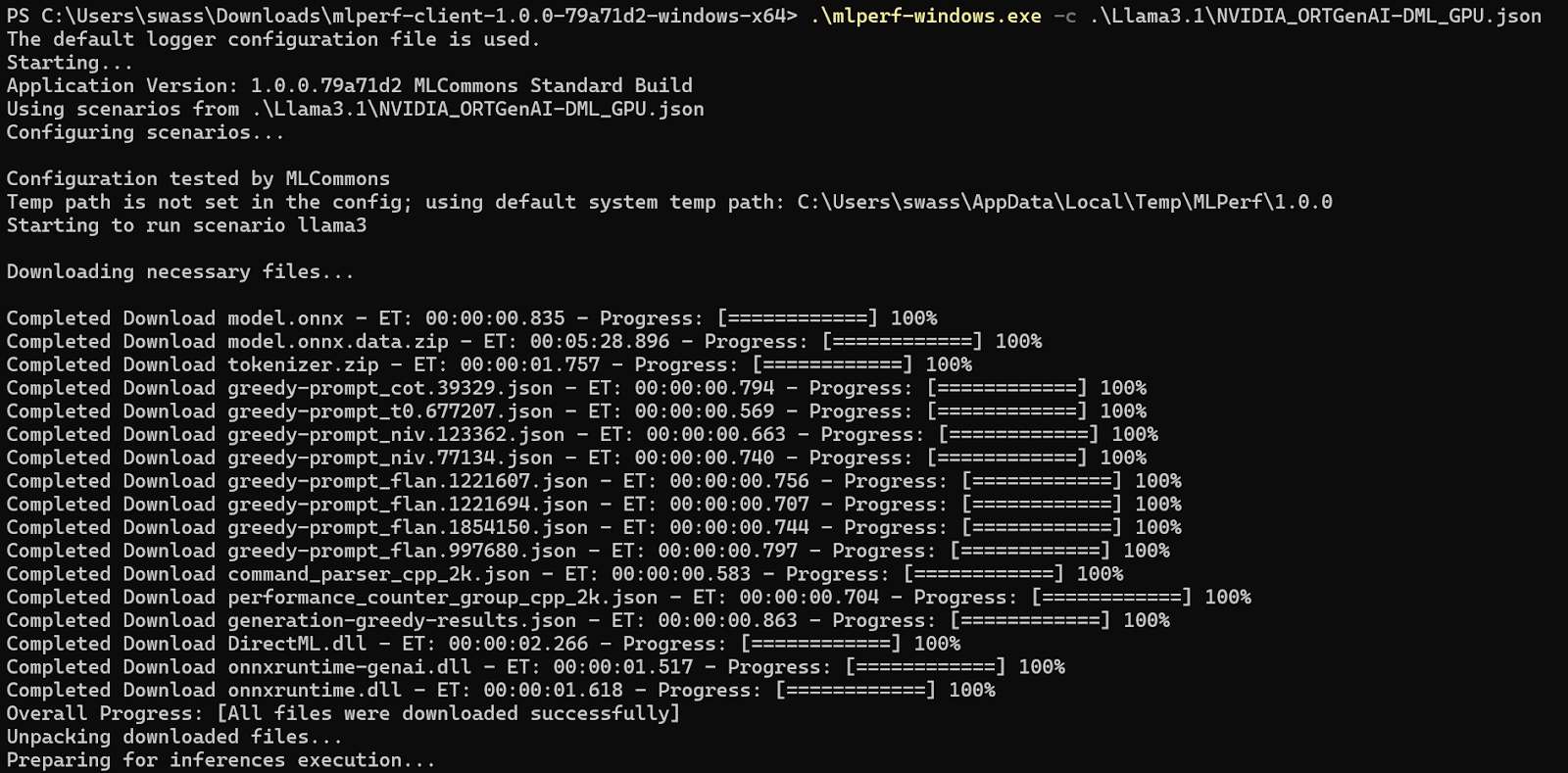
Once you’ve kicked off the test run, the benchmark should begin downloading the files it needs to run. Those files may take a while to download. For instance, for the ONNX Runtime GenAI path, the downloaded files will total just over 7GB.
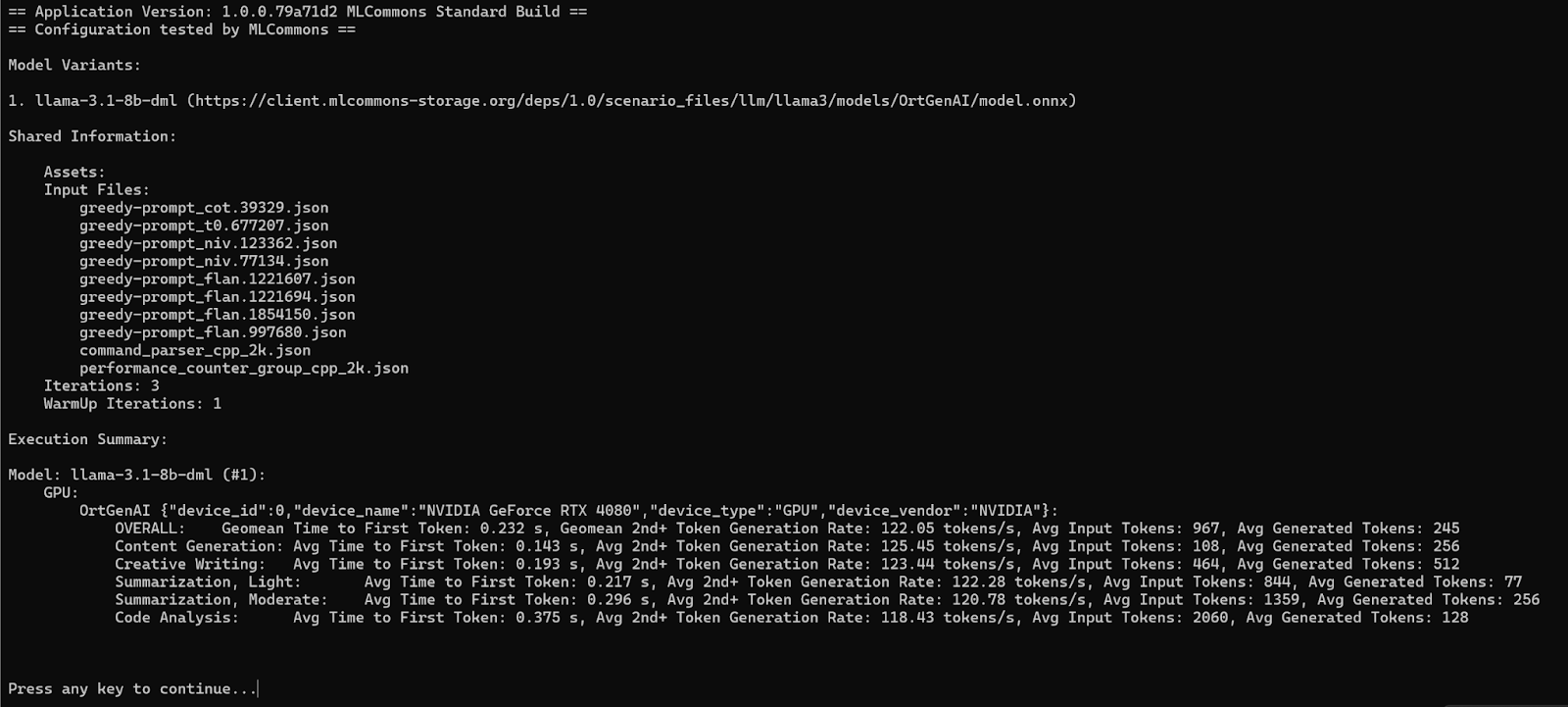
After the downloads are complete, the test begins automatically. While running, there is a progress bar indicating the stage of the benchmark. When complete, the results are displayed as below.
What are these “configuration tested” notifications?
The MLPerf Client benchmark was conceived as more than just a static test. It offers extensive control and configurability over how it runs, and the MLPerf Client working group encourages its use for experimentation and testing beyond the included configurations.
However, scores generated with modified executables, libraries, or configuration files are not to be considered comparable to the fully tested and approved configurations shipped with the benchmark application.
When the benchmark begins to run with one of the standard config files, you should see a notification in the output that looks like this:

This “Configuration tested by MLCommons” note means that both the executable program and the JSON config file you are using have been tested and approved by the MLPerf Client working group ahead of the release of the benchmark application. This testing process involves peer review among the organizations participating in the development of the MLPerf Client benchmark. It also includes MMLU-based accuracy testing. Only scores generated with this “configuration tested” notice shall be considered valid MLPerf Client scores.
Does the benchmark require an Internet connection to run?
Only for the first run with a given acceleration path. After that, the downloaded files will be stored locally, so they won’t have to be downloaded again on subsequent runs.
Do I need to run the test multiple times to ensure accurate performance results?
Although it’s not visible from the CLI, the benchmark actually runs each test four times internally in the default configuration files. There’s one warm-up run and three performance runs. The application then reports the averages of the results of the three performance runs.
My system has multiple GPUs. On which GPU will the test run? Can I specify which GPU it should use?
By default, the GPU-focused configs in MLPerf Client do not specify a particular device on which to run, so the benchmark will run on all available GPUs, one at a time, and report results for each.
In the CLI, to see a list of the GPUs available to run a particular config, use the -e switch on the command line while specifying the config as usual with -c <config name>.

Once you have a list of devices, you can use the -i switch to specify on which device the benchmark should run, like so:

The benchmark should then run only on the specified device.
My system has an integrated GPU from one company and a discrete GPU from another. How should I run the benchmark?
The preferred path for each vendor is using its own config file. So, for example, we recommend using the Nvidia ORT GenAI config file to run on the discrete GeForce GPU while using the AMD ORT GenAI GPU config file to run on the integrated AMD GPU.
See above for instructions on how to specify which GPU the benchmark should use with each config.
The benchmark doesn’t perform as well as expected on my system’s discrete GPU. Any ideas why?
See the questions above about the benchmark running on multiple devices. Make sure the benchmark results you are seeing come from your system’s discrete GPU, not from an integrated graphics processor. If needed, specify the device as described above to ensure you’re testing the right GPU.
How can I contribute to the ongoing development of MLPerf Client?
For details on becoming a MLCommons member and joining the MLPerf Client working group, please contact [email protected].