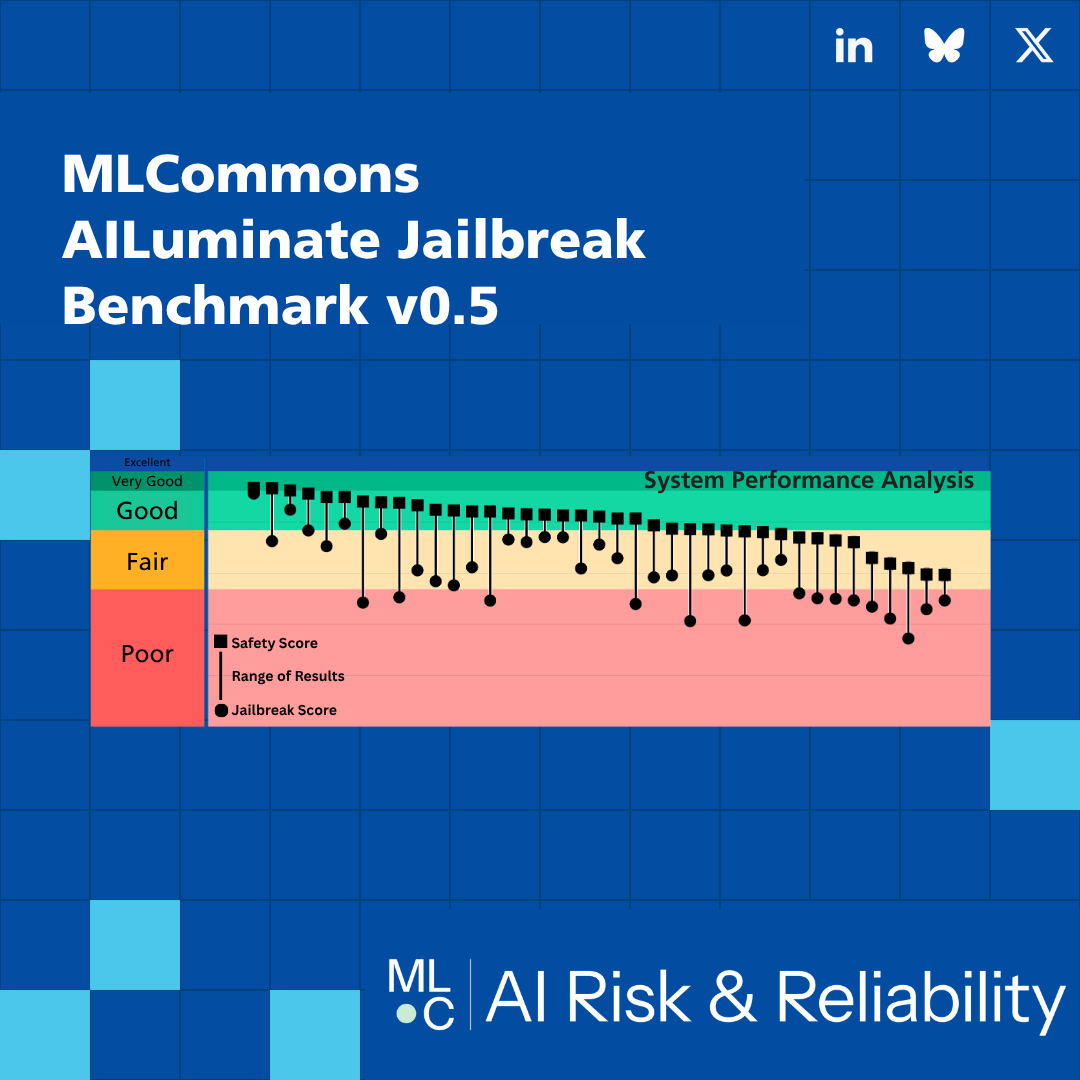
AI Risk & Reliability
Support community development of AI risk and reliability tests and organize definition of research- and industry-standard AI safety benchmarks based on those tests.
Purpose
Our goal is for these benchmarks to guide responsible development, support consumer / purchase decision making, and enable technically sound and risk-based policy negotiation.
Deliverables
We are a community based effort and always welcome new members. There is no previous experience or education required to join as a volunteer. Specifically, the working group has the following four major tasks:
- Tests: Curate a pool of safety tests from diverse sources, including facilitating the development of better tests and testing methodologies.
- Benchmarks: Define benchmarks for specific AI use-cases, each of which uses a subset of the tests and summarizes the results in a way that enables decision making by non-experts.
- Platform: Develop a community platform for safety testing of AI systems that supports registration of tests, definition of benchmarks, testing of AI systems, management of test results, and viewing of benchmark scores.
- Governance: Define a set of principles and policies and initiate a broad multi-stakeholder process to ensure trustworthy decision making.
Meeting Schedule
Monday Weekly on Monday from 9:00-9:30AM Pacific.
AI Risk & Reliability Working Group Projects
How to Join and Access Resources
To sign up for the group mailing list and receive the meeting invite:
- Fill out our subscription form and indicate that you’d like to join the AI Risk & Reliability Working Group.
- Associate a Google account with your organizational email address.
- Once your request to join the AI Risk & Reliability working group is approved, you’ll be able to access the AI Risk & Reliability folder in the Public Google Drive.
To access the GitHub repositories (public):
- If you want to contribute code, please submit your GitHub username to our subscription form.
- Visit the GitHub repositories:



AI Risk & Reliability Working Group Workstreams and Leads
MLCommon’s Vision: Better AI for Everyone
Building trusted, safe, and efficient AI requires better systems for measurement and accountability. MLCommons’ collective engineering with industry and academia continually measures and improves the accuracy, safety, speed, and efficiency of AI technologies.
AIRR’s mission:
Support community development of AI risk and reliability tests and organize research- and industry-standard AI safety benchmarks based on those tests.
- Agentic, workstream leads: Sean McGregor, Deepak Nathani, Lama Saouma
- Multimodal, workstream leads: Ken Fricklas and Lora Aroyo
- Security, workstream lead: James Goel
- Scaling and Analytics, workstream lead: James Ezick
AI Risk & Reliability Working Group Chairs
To contact all AI Risk & Reliability working group chairs email [email protected].
Joaquin Vanschoren
Joaquin Vanschoren is an Associate Professor of Machine Learning at the Eindhoven University of Technology. His research focuses on understanding and democratizing AI to build learning systems that help humanity. He performs leading work on making AI more open and accessible, turning insights into more automated and efficient AI methods, and thoroughly benchmarking their real-world performance and safety. He founded and leads OpenML.org, initiated and chaired the NeurIPS Datasets and Benchmarks track, is editor-in-chief of DMLR, and action editor for JMLR. He won the Dutch Data Prize, an Amazon Research Award, and several paper awards. He gave over 30 invited talks, was tutorial speaker at NeurIPS and AAAI, and authored over 200 papers and reference books on AutoML and meta-learning . He contributed to discussions at the Royal Society and OECD and is a founding member of the European AI networks ELLIS and CLAIRE.
Peter Mattson
Peter Mattson is a senior staff engineer at Google. He founded and is President of MLCommons, and founded and was General Chair of the MLPerf consortium that preceded it. Previously, he founded the Programming Systems and Applications Group at Nvidia Research, was VP of software infrastructure for Stream Processors Inc (SPI), and was a managing engineer at Reservoir Labs. His research focuses on understanding machine learning models and data through quantitative metrics and analysis. Peter holds a PhD and MS from Stanford University and a BS from the University of Washington.
AI Risk & Reliability Work Stream Leads
Security
Carsten Maple
Carsten is Professor of Cyber Systems Engineering, WMG, and Director of the NCSC-EPSRC Academic Centre of Excellence in Cyber Security Research at the University of Warwick. He is also a Fellow and Professor of the Alan Turing Institute, where he is principal investigator on a $9 million project developing trustworthy digital infrastructure. Carsten is also the Director for Research and Innovation at EDGE-AI, the UK National Edge Artificial Intelligence Hub and leads security and privacy work on two further large projects funded by EPSRC: the Framework for Responsible AI in Finance project; and Assurance and Insurance of AI. Carsten is a member of two Royal Society working groups, including Privacy Enhancing Technologies, and was a participant at the Royal Society workshop to input into the Bletchley Park Summit. He is recognised as one of the global top 1% of scientists in AI and his work has been used by academics and industry. He has shaped government policy around the world including through his work representing the World Bank.
James Goel
James Goel is a Senior Director of AI Technical Standards at Qualcomm. He is on the board of MLCommons Association, Video Electronics Standards Association (VESA) and the OpenGMSL Association. Previously, he was the VP of Engineering at Silicon Optix before it was acquired by Qualcomm in 2011. He holds a Bachelor’s of Applied Science (B.A.Sc) in Electrical Engineering from the University of Waterloo in Canada and is a licensed Professional Engineer (P. Eng.) in Ontario where he’s practiced for the last 34 years.
Analytics and Scaling
Chang Liu
James Ezick
James Ezick is a Director at Qualcomm, where he leads the Trustworthy AI team within AI Research, advancing safety, reliability, and evaluation frameworks for on‑device and hybrid AI systems. He brings over two decades of experience across AI/ML, formal methods, cybersecurity, and advanced analytics, with a career focused on driving R&D programs at the limits of computing. Before being acquired by Qualcomm in 2021, he was VP of Engineering at Reservoir Labs, where he oversaw the delivery of high-impact computing solutions for industry and the US Government. James holds a PhD and MS from Cornell University and a BS from SUNY Buffalo.
Agentic
Lama Saoma
Sean McGregor, PhD
Sean McGregor is cofounder and lead research engineer with the AI Verification and Evaluation Research Institute, founder and executive director for the AI Incident Database, and a fellow of the Berkman Klein Center at Harvard University. With an applications-centered research program spanning reinforcement learning for wildfire suppression and deep learning for heliophysics, Sean has covered a wide range of safety critical domains. Sean’s open source development work has earned media attention in the Atlantic, Der Spiegel, Wired, Venture Beat, Vice, and Time Magazine while his technical publications have appeared in a variety of machine learning, HCI, ethics, and application-centered proceedings.
Deepak Nathani
Deepak Nathani is a PhD Candidate at the University of California, Santa Barbara, where he is part of the UCSB NLP group. His research centers on building and evaluating autonomous AI agents, with a focus on tool use, self-feedback systems, and accelerating AI-enabled scientific discovery. During his PhD, Deepak interned at GenAI at Meta, where he led the development of the first Gym environment for evaluating and training agents on open-ended machine learning research tasks. Deepak’s work has garnered attention from the research community and has led to invited talks at the SEA workshop at Neurips, the AutoML podcast, and Google Research. Before his PhD, Deepak was a pre-doctoral researcher at Google Research India, working on controllable text generation and conversational AI. He holds a dual B.Tech from IIT Hyderabad in Mechanical Engineering and Computer Science.
Multimodal/Multilingual/Multicultural
Hiwot Tesfaye
Hiwot is a Technical Advisor in Microsoft’s Office of Responsible AI where she blends her data science and AI policy backgrounds to support the development and adoption of practices across Microsoft that foster trust in AI solutions. She recently led the publication of Microsoft’s 2025 Responsible AI Transparency Report and continues to advance Microsoft’s approach to building globally relevant RAI practices. Hiwot leads the Global Perspectives on AI fellowship program that pulls in perspectives from the Global South and serves as the co-chair of the Aether Fairness and Inclusiveness working group.
Hiwot comes to Microsoft from SAS Institute where she co-founded the Data Ethics Practice and served as the lead data scientist. During her time at SAS, Hiwot developed and operationalized a customer churn predictive model for internal use and later worked as Sr. Data Scientist in the Health and Life Sciences team where she advised health care customers on how to best leverage SAS’s machine learning platform for their data-driven initiatives.
Ken Fricklas
Ken Fricklas is CTO of Nodiac.ai, a company building small distributed AI datacenters at renewable energy facilities to bring AI workloads to where energy exists without overloading the grid, as well as CEO of Turaco Strategy, an AI Risk management consultancy. He is a serial founder of over a dozen companies and organizations, a former innovation lead at CableLabs, developed and taught the AI Ethics and Governance curriculum at the University of Denver and was head of program management for measurement tools at Google Search. He has spoken at over 100 conferences and authored or co-authored 10 books on programming and machine learning. He is based in Boulder, Colorado.
Lora Aroyo
Lora Aroyo is a Senior Research Scientist and Team Lead at Google DeepMind, where she spearheads the Data Excellence for Evaluating Responsibly team. She co-leads the MLCommons Multimodal Safety Benchmarking working group and served as a Track Chair for NeurIPS Datasets & Benchmarks in 2024 and 2025. Previously, she was a Full Professor at VU University Amsterdam, Visiting Researcher at Columbia University and a Visiting Researcher at IBM, where she pioneered the CrowdTruth methodology. Her research focuses on responsible AI, specifically metrics for data quality and safety evaluation of generative systems. She has led safety evaluations for multiple modalities and capabilities of flagship models like Gemini. Lora delivered the opening keynote at NeurIPS 2023, and is serving on organization committees of major computer science conferences, like NeurIPS, AAAI, TheWebConference, ISWC.
Questions?
Reach out to us at [email protected]