
Introduction
MLPerf Tiny, introduced in August 2021, is the first industry-standard benchmark suite testing performance at inference across ultra-low-power tiny machine learning systems. Developed from the collaborative effort of over 50 organizations, the MLPerf Tiny benchmark suite arose from the need to evaluate devices that process these “tiny” neural networks in a fair, standardized, and reproducible manner. These tiny networks, typically with fewer than 1 million parameters, handle sensory inputs such as audio and vision to bring AI capabilities to power-constrained form factors. With TinyML, inference occurs directly on-device and near sensors, resulting in faster responses and enhanced privacy. This approach sidesteps the high energy costs of wireless data transmission, often a much larger drain than the computation itself.
The goal of MLPerf Tiny is to provide a representative set of deep neural nets and benchmarking code to compare performance between embedded devices. Embedded devices include microcontrollers, Digital Signal Processors (DSPs), and tiny neural network accelerators. These devices typically run at between 10MHz and 250MHz, and can perform inference with less than 50mW of power.
MLPerf Tiny Benchmark Suite
The MLCommons Tiny Working Group spearheads the development and ongoing management of MLPerf Tiny. To ensure fairness, comparability, and to foster innovation, MLPerf Tiny operates with two distinct divisions:
Closed Division: This division focuses on “apples-to-apples” comparisons. Submissions must use the same specified model, dataset, and metrics, allowing for direct hardware comparisons where only the underlying hardware and optimized software stack are variables.
Open Division: This division encourages broader innovation by allowing submitters to use different or custom models, datasets, or training methods.
Three key metrics – accuracy, latency and energy – are used to weigh the tradeoffs between systems across tasks such as keyword spotting, visual wake words, image classification, and anomaly detection. A dataset and quality target define each of these task-specific benchmarks.
Keyword Spotting
Wake word detection, a type of keyword spotting mainly used for voice applications, is a popular application of a TinyML use case. Low power consumption, cost, and latency are critical for wake word detection to continuously monitor for a specific word or phrase. This Keyword Spotting benchmark leverages the Speech commands v2 dataset, which contains utterances from speakers with a diverse range of accents. A small depth-wise convolutional neural network (CNN) is used in the closed division of this benchmark. At 38.6K parameters, it fits the memory requirements for most resource-constrained devices. An accuracy requirement of 90% is set in this Keyword Spotting benchmark to account for slight variations from quantization strategies.
Visual Wake Words
The Visual Wake Words Challenge resembles a common microcontroller vision use-case of identifying whether a person is present in an image or not (e.g., smart doorbell applications).
The MSCOCO 2014 dataset is used for training, validation, and testing, with images resized to 96×96 pixels. The model used is a MobileNetV1 with two output classes: “person” and “no person”. The 80% accuracy quality target metric is to account for the changes in accuracy that occur from quantizations and rounding differences between platforms.
Image Classification
As advancements in machine vision enable compact, efficient, and high-performance embedded systems, they are revolutionizing manufacturing, IoT, and autonomous technology. Consequently, there is a rising demand for standardized evaluation frameworks to classify images using embedded devices.
The Image Classification benchmark of MLPerf Tiny uses the CIFAR-10 dataset, which contains 60,000 32x32x3 RGB images across 10 classes (e.g., airplanes, cars, cats, dogs). A custom ResNetv1 model, which is a modified version of the official ResNet, takes these 32x32x3 images as input and produces a probability vector of size 10. The quality target for this benchmark is 85% top-1 accuracy to accommodate minor differences in quantization and various other optimizations.
Anomaly Detection
Anomaly detection separates normal from anomalous samples using unsupervised learning. This is crucial for industrial applications like machine failure detection, where failure data is scarce and training relies mainly on data of standard operation. The Anomaly Detection benchmark of MLPerf Tiny utilizes unsupervised learning with an autoencoder (AE) model, serving as the reference implementation in the DCASE2020 competition, alongside the toy-car machine subset of its dataset. The threshold for this benchmark was set to AUC 0.85.
How MLPerf Tiny Overcame Traditional Challenges with Benchmarking TinyML
Overcoming Memory Limitations
Memory limitations pose a challenge for TinyML systems, as even a benchmark’s overhead can exceed a device’s capacity. To overcome this, the MLPerf Tiny suite is designed with compactness in mind. It accommodates diverse hardware by allowing multiple quantization levels and precision variants. A lightweight communication protocol is used over a standard UART (Universal Asynchronous Receiver/Transmitter) interface to minimize the memory footprint for data transfer. Additionally, the benchmarks use efficient models specifically selected to test common computational patterns while remaining within the tight memory and storage constraints of most embedded devices.
Overcoming Hardware and Software Heterogeneity
The TinyML landscape is highly fragmented, with a vast array of microcontrollers, custom accelerators, and specialized processors. This hardware heterogeneity poses a significant challenge for traditional benchmarks, which were often designed for more uniform computing environments.
To address this, the MLPerf Tiny benchmarks take a unique approach by focusing on the model itself, rather than the underlying hardware or software implementation.
Even in the closed division, there are no instruction-level requirements. The only rule is that the submitted model must be mathematically equivalent to the reference model. This design enables a wide range of hardware platforms to implement and optimize the benchmark, accommodating various architectures and specialized accelerators.
Similarly, the diversity of software stacks in the TinyML space presents a challenge for achieving consistent and reproducible measurements. Software optimizations are often tightly coupled with specific hardware platforms, making a one-size-fits-all approach impractical. The MLPerf Tiny benchmarks acknowledge this software heterogeneity by avoiding constraints on specific machine learning runtimes, libraries, or other software components. Any system submitted to the closed division only needs to implement a model mathematically equivalent to the reference and support a minimal communication protocol.
This flexibility is demonstrated with the benchmark suite’s modular design, which has enabled a wide variety of systems that use both open-source and proprietary runtimes to participate in the benchmarks.
Modular Design
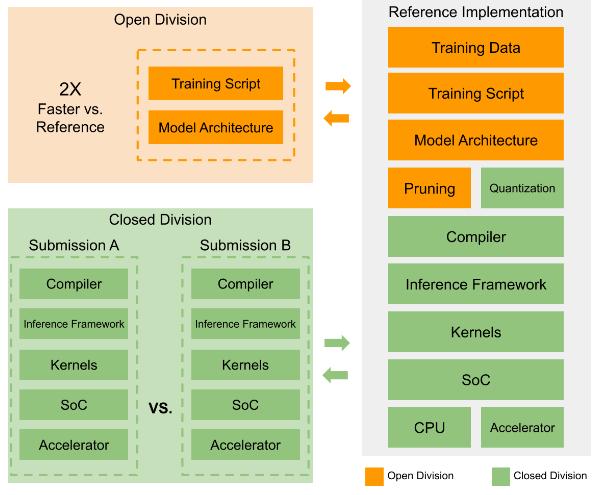
The modular design of MLPerf Tiny allows for flexible benchmarking and direct comparisons between different solutions. Each benchmark has a reference implementation that includes everything from the training data and script to a reference hardware platform. This provides a baseline result, allowing submitters to modify specific components and demonstrate their competitive advantage.
The components of the benchmark are divided into two categories in the figure below.
- Green components (e.g., Quantization, Compiler, Inference Framework, Kernels, SoC, CPU, and Accelerator) can be modified in both the Open and Closed divisions.
- Orange components (e.g., Training Data, Training Script, Model Architecture, Pruning) can only be modified in the Open division.
Limitations of MLPerf Tiny
One limitation of this benchmark suite is that it doesn’t account for continuous streaming inputs, where information from previous time steps stays relevant for future inference cycles. The prior energy measurements didn’t accurately reflect duty-cycled deployment scenarios, which are common in real-world applications. Additionally, the earlier benchmark’s feature extraction was performed on the host, which is not representative of typical on-device processing. Finally, the use of static inference created ambiguity regarding the data loading process, making it difficult to get an accurate picture of performance. To address these limitations, MLCommons introduces a new streaming benchmark in the current iteration (V1.3).
A New Streaming Benchmark
The streaming benchmark evaluates the real-time detection of a wake word, such as “Hey Siri” or “Alexa,” in a noisy audio stream. The specific wakeword used for this test is “Marvin,” selected because it has the most recorded samples among the multi-syllabic and non-numeric words in the Speech Commands dataset.
The test uses a synthesized 20-minute audio recording that includes 50 instances of the “Marvin” wake word, along with various background noises like music, speech, and traffic. This scenario mimics real-world applications where a device needs to identify a specific sound pattern consistently.
A 1D time-separable model, similar to Nvidia’s Matchbox model, was chosen for its balance of performance and efficiency. The model was trained on the wakeword itself, other words from the Speech Commands dataset, and a variety of background noises. This approach isn’t limited to wakeword detection; it can be applied to other acoustic events like gunshots or baby cries, or even non-acoustic events like vibrational patterns in industrial monitoring.
A key challenge in this streaming benchmark is the real-time synchronous delivery and collection of input and output. To ensure accuracy, a detection is considered correct only if it occurs within one second of the end of the actual wakeword.
A microcontroller unit (MCU)-based interface board was used to synchronize the system. It delivered audio to the device under test (DUT) and recorded a timestamp whenever the DUT pulsed a GPIO (General Purpose Input/Output) pin to signal a detection.
The interface board also measured two other critical metrics:
Duty Cycle: A second GPIO signal from the DUT indicates when it was actively processing. The interface board captures this “Active” signal to measure the duty cycle, which represents the percentage of time the processor is busy. A low duty cycle is desirable, as it means the device has spare processing cycles for other tasks.
Power Consumption: A power monitor measures the DUT’s energy usage. An efficient system must not only run the neural model with low energy but also quickly transition to a low-power idle state when not processing audio.
MLPerf Tiny v1.3 Benchmark Overview
| Task | Dataset | Model | Mode | Quality | Latest Version Available |
|---|---|---|---|---|---|
| Keyword Spotting | Google Speech Commands | DS-CNN | Single-stream, Offline | 90% (Top 1) | v1.3 |
| Visual Wake Words | Visual Wake Words Dataset | MobileNetV1 0.25x | Single-stream | 80% (Top 1) | v1.3 |
| Image classification | CIFAR10 | ResNet-8 | Single-stream | 85% (Top 1) | v1.3 |
| Anomaly Detection | ToyADMOS | Deep AutoEncoder | Single-stream | 0.85 (AUC) | v1.3 |
| Streaming Wakeword | Custom Speech Commands + MUSAN | 1D DS-CNN | Streaming | False Positive, <= 7 False Negative | v1.3 |
Top-1 accuracy is a metric used in multi-class classification to evaluate the performance of a model. For example, an 85% top-1 accuracy for image classification means that for 85% of the images tested, the model’s highest-confidence prediction was the correct one.
Conclusion
MLPerf Tiny provides an industry-standard benchmark suite for evaluating ultra-low-power tiny machine learning systems. It addresses challenges like memory limitations and hardware/software heterogeneity through its compact and flexible design, offering both a Closed Division for direct comparisons and an Open Division for innovation. The suite utilizes metrics such as accuracy, latency, and energy across various tasks, including keyword spotting, visual wake words, image classification, and anomaly detection. Notably, a new streaming benchmark has been introduced to address previous limitations, focusing on real-time detection and incorporating measurements of duty cycle and power consumption.
Call to Action
We invite you to learn more about MLPerf Tiny and get involved. Explore the benchmarks, review the results, and consider joining the MLCommons Tiny Working Group. Your contributions will help shape the future of TinyML. Additionally, we are seeking interviewees to gather community input and explore possibilities for enriching new benchmarks.