
The Medical WG at MLCommons has been maintaining best practices for enabling real-world benchmarking and evaluation of AI/ML models in healthcare. MedPerf is an open-source orchestrator developed by the community. It has been supporting the most extensive AI clinical research study in glioblastoma [Federated Learning for Postoperative Segmentation of Treated glioblastoma (FL-PoST)]. During this time, we have been enhancing MedPerf’s capabilities, including data preparation pipelines and monitoring [MLCommons Medical WG Supports FeTS 2.0 Clinical Study with MedPerf and GaNDLF].
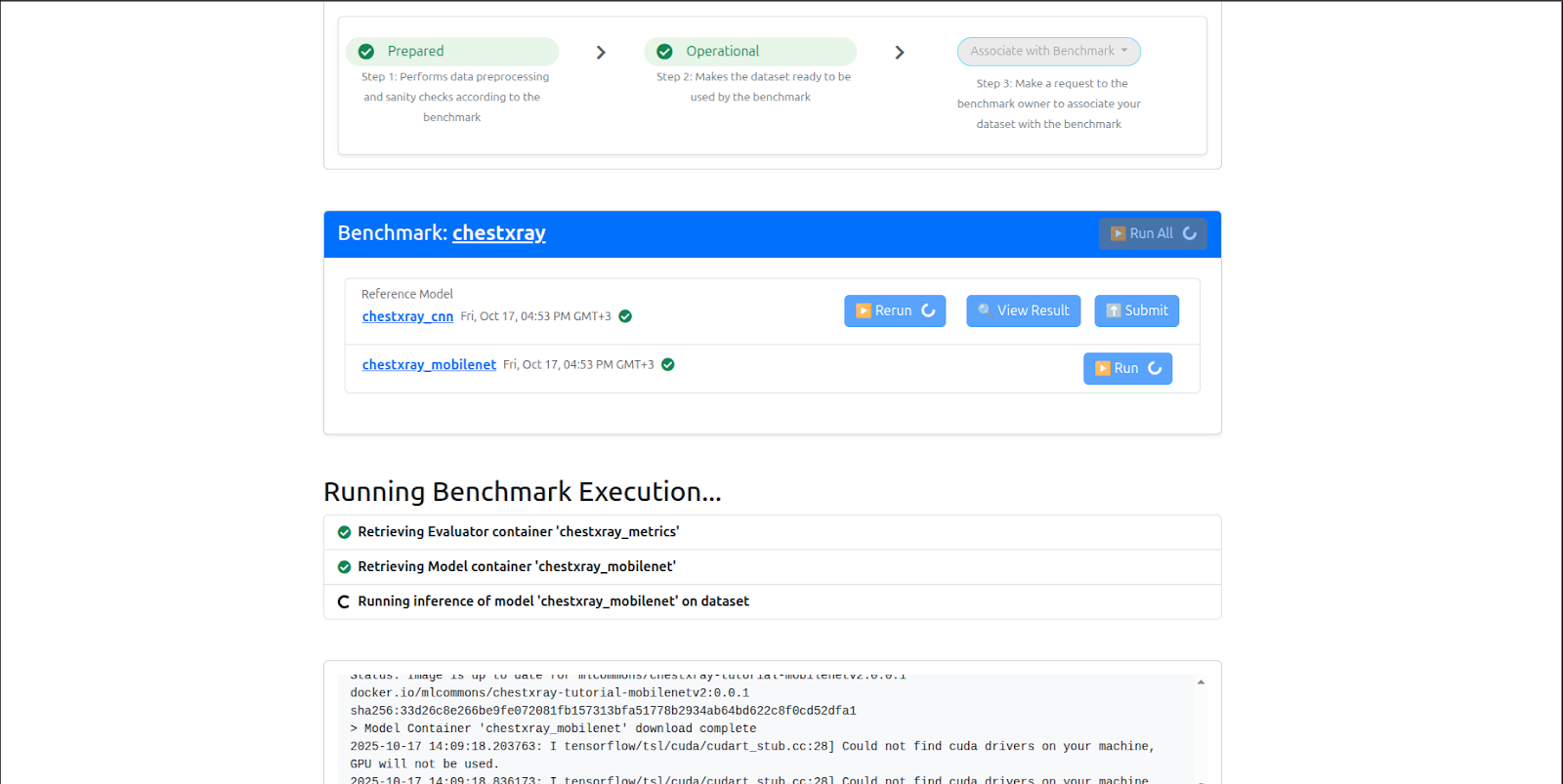
Today, we are announcing that MedPerf has added WebUI capabilities, making it easier for benchmark creators to orchestrate. The WebUI extends Medperf’s capabilities to the browser, providing an intuitive interface built on its CLI. Running entirely on the local machine, the WebUI executes the same commands and functions as the CLI, offering a more visual, accessible way to interact with Medperf without changing how it works under the hood. Access is secured by a unique token generated at launch, ensuring that access remains restricted to the user who launched it. By combining the power of the CLI with the convenience of a browser, Medperf WebUI aims to deliver a user-friendly experience to all Medperf users, including non-technical experts (e.g. clinicians).
We tested the WebUI in our current clinical study for glioblastoma to facilitate the evaluation of AI models on 1568 brain scans across 7 data sites from North America and Europe. Through the WebUI the study’s principal investigator, Dr. Evan Calabrese, followed a step-by-step workflow to create a validation record accompanied by the data preparation script, the metrics script and the model under evaluation, which was pre-trained on 10208 brain scans across 53 data sites from 5 continents (North America, South America, Europe, Asia, and Australia) in the first phase of the study via federated learning using Intel’s OpenFL. Through the WebUI, the representative from each evaluation site followed a step-by-step workflow to prepare the data locally and initiate the evaluation. Evaluation results were monitored via the principal investigator’s dashboard on the WebUI.
We also created an online tutorial for new MedPerf users to learn how to use the new WebUI in easy steps which can be found here: Full Tutorial (WebUI) – MedPerf.
Dr. Evan Calabrese, the lead principal investigator for the clinical study mentioned:
“The MedPerf WebUI was beneficial for the validation phase of the Federated Learning for Postoperative Segmentation of Tumors (FL-PoST)/Federated Tumor Segmentation (FeTS) 2.0 study, which required international collaboration across ~10 different academic medical centers to validate our brain tumor segmentation model trained on over 10,000 individual MRI exams from >35 institutions. In particular, the familiar web-based interface enabled efficient collaboration across time zones without the need for live support, even for those with limited technical literacy. Using the MedPerf WebUI, we were able to work asynchronously across seven individual external sites without any significant support delays. Once we completed the validation phase, the results could be easily viewed or downloaded from the WebUI on our end. It’s clear to me that this WebUI will be the future of MedPerf, enabling broader collaboration without increased support burden.”
Other feedback from clinical and academic contexts included:
“Click and click, step-by-step, all necessary information included in the webUI manual. Web UI was easy to follow, and intuitive to understand the current evaluation status!”
Jaeyoung Cho, CCIBonn.ai, University Hospital Bonn
“The MedPerf Web UI offers an intuitive and user-friendly interface that can be easily operated by both engineers and clinicians with minimal learning effort. As a standardized evaluation platform, it simplifies the benchmarking of models across datasets using multiple performance metrics, facilitating both clinical deployment and future research. I particularly appreciate its integration with compute cluster environments via Docker or Singularity, which makes installation and setup straightforward for any user.”
Rachit Saluja, PhD student, Cornell University & Weill Cornell Medicine
“The interface was easy to learn, and having the post-pipeline segmentations easily accessible through ITK-snap in the UI made processing the segmentations much quicker. It was very convenient to receive multiple labels to show the different components of the segmentations.“
Erik Elgeskog, University of Gothenburg
A Call to Action
We invite the research and medical AI community to explore the new MedPerf WebUI and experience a more accessible way to benchmark and validate models. Your participation is vital to our growth; we encourage you to test the interface, collaborate with peers, and report both your technical hurdles and your success stories to help us refine the platform. Beyond testing, this is an invitation to make a tangible impact: join us in our ongoing AI-based clinical studies and help accelerate the adoption of trusted medical AI
About MedPerf
MedPerf is an open benchmarking platform that aims at evaluating AI on real-world medical data. MedPerf follows the principle of federated evaluation in which medical data never leaves the premises of data providers. Instead, AI algorithms are deployed within the data providers and evaluated against the benchmark. Results are then manually approved for sharing with the benchmark authority. This effort aims to establish global federated datasets and develop scientific benchmarks to reduce the risks of medical AI, such as bias, lack of generalizability, and potential misuse. We believe this two-pronged strategy will enable clinically impactful AI and improve healthcare efficacy.
Learn more at https://mlcommons.org/working-groups/data/medical/.
About MLCommons
MLCommons is an open engineering consortium with a mission to make machine learning better for everyone. The organization produces industry-leading benchmarks, datasets, and best practices that span the full range of ML applications—from massive cloud training to resource-constrained edge devices. Its MLPerf benchmark suite has become the de facto standard for evaluating AI performance.
Learn more at www.mlcommons.org.