
Introduction
Croissant aims to create a universal machine-readable metadata format for machine learning (ML) datasets. Led by MLCommons and with contributions from more than 30 organizations, Croissant enhances interoperability, reproducibility, and accessibility across ML tools and stakeholders, including engineers, responsible AI researchers, and policy makers. The metadata specification is designed for ML datasets, ensuring datasets are “AI-ready” and easily portable across workflows.
Developers and data scientists increasingly rely on large language models (LLMs) to work with datasets. LLMs can analyze data and generate useful data processing code. As the examples below demonstrate, there is a significant benefit in exposing Croissant datasets to LLMs, as Croissant provides rich, structured descriptions of datasets. With Croissant, an LLM can easily interrogate a dataset’s metadata as well as the data to provide more reliable and insightful answers.
Croissant with MCP
The Model-Context-Protocol (MCP) has emerged as a powerful mechanism for LLMs to use third-party services by calling tools, seeking out resources, and requesting prompts. With MCP, services provide guidance on when and how an AI model should utilize them, as well as a standardized API description that includes input and output formats, ethical guardrails, and data boundaries. In practice, MCP is being used to extend LLMs with agentic capabilities, often in software development environments, to call out to various tools and access data endpoints such as authoritative datasets (e.g. statistics, weather) or datasets that are updated frequently.
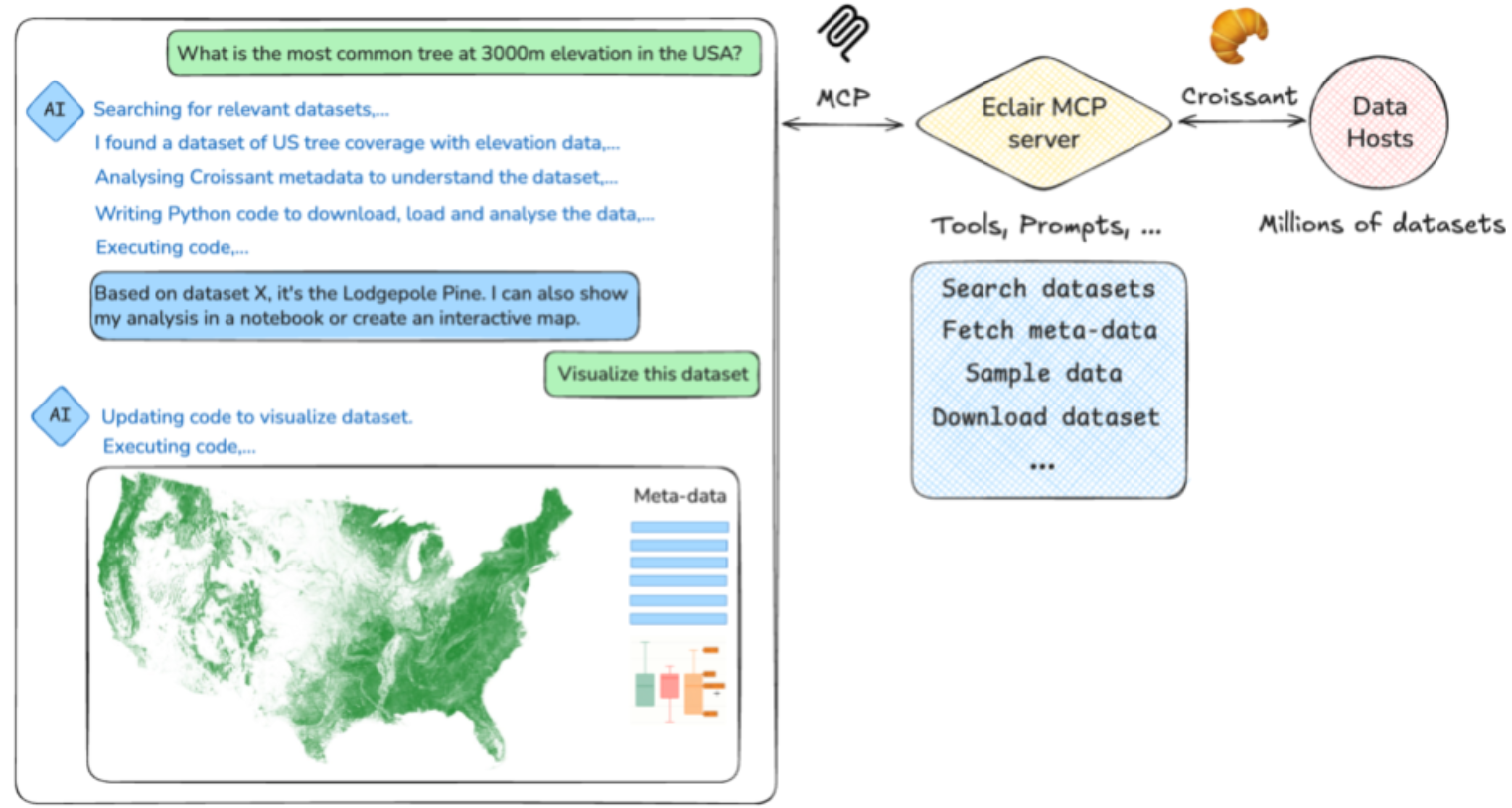
Envisioned interaction between an LLM chat application and the Eclair MCP server. Eclair enables the LLM to search for Croissant datasets, inspect their metadata and data, and answer user questions by generating data visualizations or other types of useful analyses.
Several public data platforms, including Google Dataset Search, Hugging Face, Kaggle, Harvard Dataverse, and OpenML, have adopted Croissant. Data scientists and ML engineers can rely on the Croissant specification to load, split, and annotate datasets to indicate how they are intended to be used. MCP servers can similarly build on Croissant to offer a range of valuable tools to LLMs, such as a ‘dataset download’ tool that provides metadata and instructions for LLMs to download and load datasets.
Introducing Eclair
We’re excited to announce Eclair, a set of agentic tools that help LLMs discover, download, and use datasets, with help from Croissant, to answer questions based on factual data. With Eclair, AI models can answer user questions by easily finding and accessing millions of datasets available all over the world, download and analyze this data on the fly to give accurate answers, reason about it and combine it with other data, as well as generate detailed analyses (e.g. notebooks) and custom UIs to explore the data in depth. It’s like having your own personal, lightning-fast data scientist.
Currently, it provides tools that assist LLMs in searching for datasets, retrieving their Croissant metadata, downloading them, and loading them into data structures, as well as instructions on how to think like a data scientist. It has an MCP server that you can run locally or remotely and can relay to other MCP servers, as well as a range of MCP clients so that you can use it within IDEs (e.g. Gemini Code Assist or Copilot in VSCode), within AI tools like Gemini CLI or Claude Code, and it has a Python API and CLI for integration into other projects. It is also easily extensible, and we hope that the community will build on it to develop and text many more useful tools for LLMs to work with datasets.
Other implementations
Over the past months, several other MCP implementations supporting Croissant have emerged. The Harvard Dataverse and Kaggle now have MCP implementations that can be run locally. By installing these services, you can talk to these endpoints and interrogate their datasets, using English or any other language supported by the LLM. For new datasets, Croissant metadata can be created using the Jetty MCP endpoint, which enables an LLM to seek help and validate the metadata interactively. Furthermore, the MLCBakery combines MCP with Croissant files in a hosted server environment. A data scientist might begin by asking the LLM to search for a relevant dataset and retrieve hosted Croissant metadata. From there, they may download a dataset preview. In other instances, they may call a Croissant validation tool remotely, thereby ensuring that the dataset metadata can be easily published and visualized.
Fortunately, several of these tools have open-source implementations that can be adapted for use with private data repositories as well. With Croissant-enabled services, it then becomes possible to associate Croissant metadata across different data platform providers, thus providing a complete story about the lineage and provenance of a given dataset.
Looking forward
From the Croissant working group, it’s become clear that MCP is an essential mechanism for improving dataset interoperability and discoverability. The working group is actively developing the next version of the specification, Croissant v1.1, which will incorporate best practices for dataset provenance, lineage, tasks, and versioning. It will be released later this year. We invite anyone working on dataset metadata to participate in the Croissant working group and share their insights on how we can improve ML dataset standardization and interoperability.