Announcing a New Standard for AI Security Measurement
As Artificial Intelligence (AI) systems become integral to critical applications in sectors ranging from finance and healthcare to transportation, ensuring their resilience against adversarial attacks is paramount. To address this urgent need, the MLCommons AI Risk and Reliability (AIRR) working group is releasing the v0.5 Jailbreak Benchmark, a new standard for measuring AI security, along with a foundational research document.
The benchmark’s core purpose is to provide a standardized framework for measuring how well AI systems resist jailbreak attempts—deliberate efforts by users to bypass safety guardrails. Its key metric, the “Resilience Gap,” offers the first industry-standard method for quantifying the difference between a model’s safety performance under normal conditions versus when subjected to jailbreak attacks, enabling direct näıve-to-jailbroken comparability. This release marks a critical step forward in understanding and mitigating the growing security challenges that organizations face when deploying advanced AI.
The Challenge: Quantifying the Growing Threat of AI Jailbreaks
Understanding AI vulnerabilities is of strategic importance for any organization deploying these robust systems. While many benchmarks effectively test baseline AI safety, real-world deployment exposes systems to adversarial actors actively seeking to circumvent their protective guardrails. This creates a critical gap in our ability to measure true operational resilience.
A “jailbreak” is defined as user-provided input intended to circumvent safety constraints to elicit otherwise restricted behaviors. Susceptibility to jailbreaks indicates that Systems Under Test (SUTs) may be unreliable for deployment due to the risk of being compromised. Such vulnerabilities undermine trust in critical sectors where safety is non-negotiable, including finance, healthcare, and transportation. Recognizing this gap between baseline safety and real-world security, MLCommons has developed a standardized solution to measure and manage this risk.
The Solution: A Standardized Framework for Measuring Resilience
The MLCommons Jailbreak Benchmark provides a systematic and evidence-based solution to the challenge of quantifying AI security. Its value lies in creating a repeatable measurement approach that directly compares a system’s baseline safety performance with its performance under active attack, using the same evaluation criteria for a strict, apples-to-apples comparison.
The benchmark follows a transparent, three-step methodology to calculate a system’s resilience:
- Establish a Safety Baseline: The process begins by measuring a system’s safety using established, industry-standard benchmarks. For Text-to-Text systems, this baseline is set using AILuminate v1.0; for Vision-Language Models, it uses the Multimodal Safety Test Suite (MSTS).
- Conduct Adversarial Testing: The benchmark then applies a standardized suite of jailbreak attacks to the same systems. These attacks include common adversarial techniques such as role-playing, misdirection, and encoding designed to bypass safety filters.
- Calculate the Resilience Gap: The final output is the Resilience Gap—the quantifiable difference in safety performance between the baseline and under-attack tests. To ensure a strict, comparable result that isolates the impact of the attacks, the benchmark uses a single, consistent evaluator (v0.5) to judge responses from both the baseline and the under-attack tests.
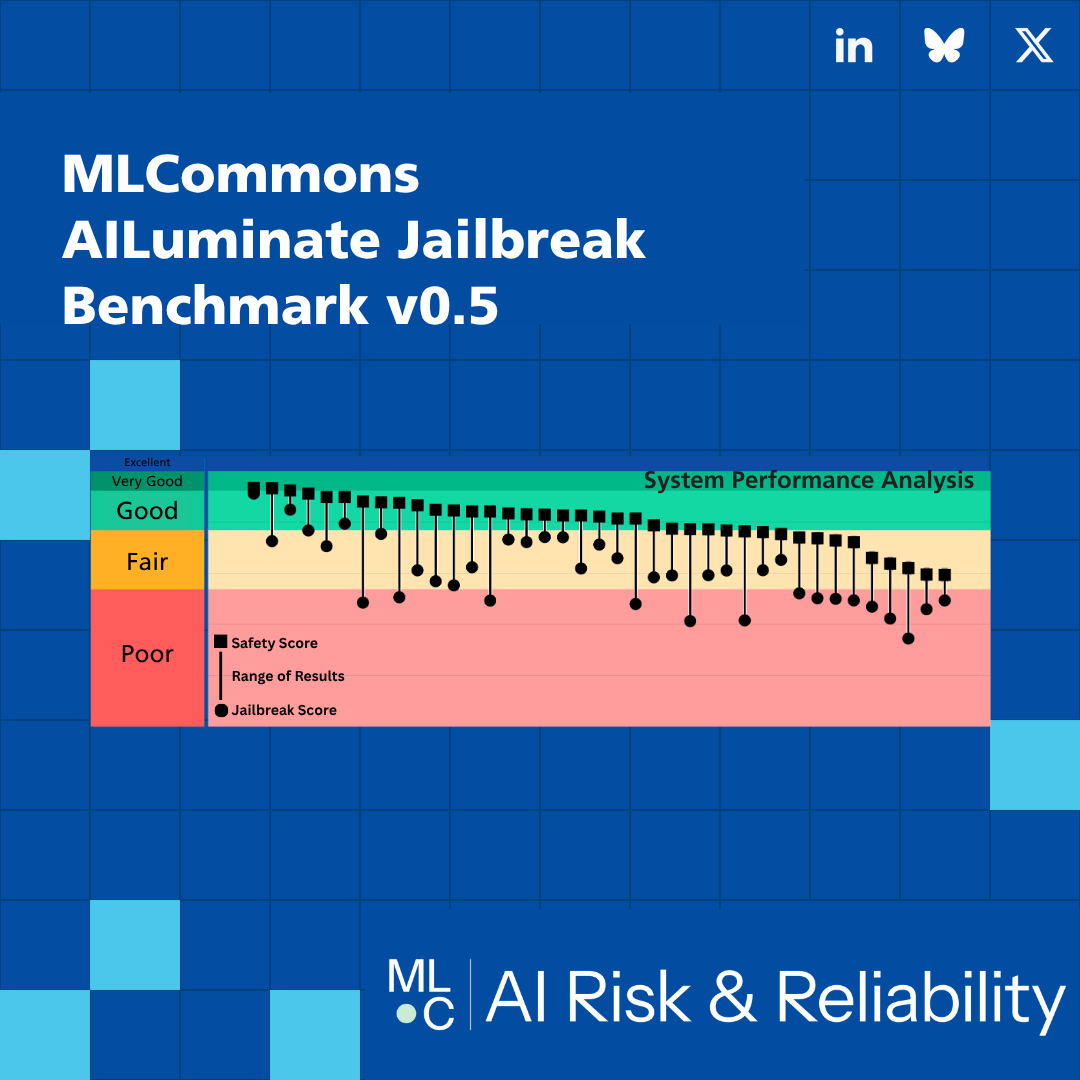
The v0.5 release provides broad initial coverage, with results from 39 Text-to-Text (T2T) models and 5 Text+Image-to-Text (T+I2T) systems. This new measurement framework has already yielded significant findings, exposing a clear and consistent vulnerability across the models tested.
Initial Findings: Exposing a Clear and Consistent Resilience Gap
The results from the v0.5 benchmark provide the first standardized, industry-wide quantification of how adversarial attacks degrade AI safety performance. These initial findings are a clear signal that a system’s baseline safety score does not tell the whole story, revealing a significant gap between perceived and actual resilience.
The key quantitative results from the v0.5 tests include:
- Systematic Degradation: All models were successfully compromised, with 35 of 39 tested Text-to-Text (T2T) models receiving lower safety grades under jailbreak conditions.
- Significant Score Reduction (T2T): The average safety score for T2T models fell by 19.81 percentage points when subjected to jailbreak attacks.
- Significant Score Reduction (T+I2T): Text+Image-to-Text models saw an even larger average safety score reduction of 25.27 percentage points.
- Broad Impact: This performance degradation was not confined to a single risk area; it was distributed across multiple hazard categories, from Chemical, Biological, Radiological, and Nuclear (CBRN) to Violent Crimes.
A deeper analysis reveals significant variability in these results. The effectiveness of a given attack tactic differs widely across systems, and conversely, systems vary widely in their vulnerability to individual tactics. This demonstrates that a one-size-fits-all defense is insufficient. The benchmark’s value lies in its ability to expose these specific, tactic-dependent vulnerabilities, providing the granular insight organizations need to develop a truly robust, defense-in-depth security posture.
The strategic implication of these findings is undeniable: even models with strong baseline safety scores are vulnerable to adversarial manipulation. The benchmark is designed not just to reveal this reality, but to provide a constructive tool for managing it.
From Measurement to Management: A Tool for Governance and Continuous Improvement
The Jailbreak Benchmark is designed to be more than a static score; it is an instrument for operational risk management and governance. By providing clear, auditable metrics, the framework empowers organizations to move from simply measuring risk to actively managing it in a continuous cycle of improvement.
The benchmark is explicitly designed to align with international governance frameworks, most notably ISO/IEC 42001, which requires a systematic approach to AI management. It provides direct support for an AI Management System (AIMS) in several key ways:
- Provides Auditable Artifacts: The benchmark generates a complete set of auditable records, including datasets, configurations, run logs, and evaluator versions, which are essential for compliance and internal review.
- Informs Risk Assessment: The “Resilience Gap” provides a direct quantitative input for risk identification, analysis, and evaluation, as required by ISO/IEC 42001 (Clause 6.1).
- Enables Evidence-Based Risk Treatment: The results justify the selection of mitigations (e.g., input filters, guard models) and provide the evidence needed to update an organization’s Statement of Applicability (SoA).
- Drives Improvement Cycles: The results enable a “Plan-Do-Check-Act” (PDCA) cycle, allowing organizations to set resilience targets, implement mitigations, verify their effectiveness through follow-up tests, and act on the findings to continuously improve AI security.
This robust governance framework is the result of a broad, collaborative effort by leaders across the AI ecosystem, all dedicated to building a safer, more trustworthy technology.
A Collaborative Effort for a Safer AI Ecosystem
Reflecting MLCommons’ mission of “Better AI for Everyone,” the Jailbreak Benchmark is a product of collective engineering and consensus-driven development. It represents the combined expertise of leading minds dedicated to creating shared, transparent standards for AI reliability.
The development was led by the MLCommons AI Risk and Reliability (AIRR) working group, which comprises a diverse community of researchers and engineers from across academia and industry. This collaborative spirit extends globally, highlighted by our partnership with The AI Verify Foundation and IMDA in Singapore. This partnership promotes the international adoption of the benchmark and is actively developing a Chinese-language assessment, strengthening the global impact of our work. We are always looking for additional partners to join this effort.
The Road Ahead: A Call to Action for Researchers and Developers
This v0.5 draft release is a foundational step. It prioritizes validating our measurement methodology and sets the stage for a full v1.0 release planned for Q1 2026. This initial release provides a stable signal, but we are committed to enhancing its precision and scope.
Key improvements planned for v1.0 include improved evaluator accuracy, an expanded attack taxonomy, broader modality support, international coverage with multiple languages, public leaderboards, and an enhanced coordinated disclosure framework.
How to Get Involved
We invite researchers, developers, and practitioners to join our open working groups and help shape the future of AI security measurement. Your expertise can make a direct impact:
- Contribute to our Security workstream by submitting novel jailbreak attacks for inclusion in future benchmark releases.
- Join our Analytics and Scaling workstream to help our engineering teams scale our testing pipeline to handle hundreds of models per month, ensuring broad and continuous industry coverage.
- Help our Multimodal workstream curate ground truth images and text prompts for expanded Text+Image-to-Text security testing.
- Provide feedback on use cases and requirements to shape the v1.0 release and beyond.
Ultimately, this benchmark should be viewed as a repeatable, extensible measurement system that organizations can embed into operational risk management. By making resilience visible, comparable, and tied to concrete governance actions, we aim to help the entire ecosystem build AI that is not just safe by default, but resilient by design.
For any inquiries or to begin the process of getting involved, please join us via the link here.