
The rapid advancement of artificial intelligence (AI) is fueling the need for complex datasets containing various high-quality text, images, audio, video, and specialized formats. Despite the growing interest in AI and its evident social impact, stakeholders face challenges in establishing reliable frameworks for responsibly sharing AI data. A significant hurdle is the absence of widely accepted, standardized contractual frameworks (i.e.: data licenses) for this purpose.
Research funded through an unrestricted grant by the MLCommons Association and recently published by the Open Data Institute (ODI) and the Pratt School of Engineering at Duke University explored the motivations driving data sharing throughout the AI ecosystem. The goal was to inform the design of more fit-for-purpose AI data licenses. A blog published by the OECD.AI/GPAI also recently featured this work.
Using a mixed-methods approach that combined interviews, an online survey, and a review of literature, this research captured a broad spectrum of insights from across eight jurisdictions and multiple sectors covering key roles such as data holders, data users, and intermediaries. Here, we give an overview of these research findings, demonstrating how standard data license agreements hold the potential to mitigate legal uncertainties, reduce transaction costs, and promote fair AI data access, particularly when combined with standard data governance and other tools.
The following key findings are organized according to four main themes: leveraging new standard data licenses to 1) promote greater data access and social good, and 2) address existing ambiguities in current contractual approaches to data sharing, alongside 3) the need for data licensing simplicity and the importance of balancing standardization with the need for some customization, and 4) developing a new standard data licensing framework to help address other data sharing challenges, including legal compliance and ethical considerations.
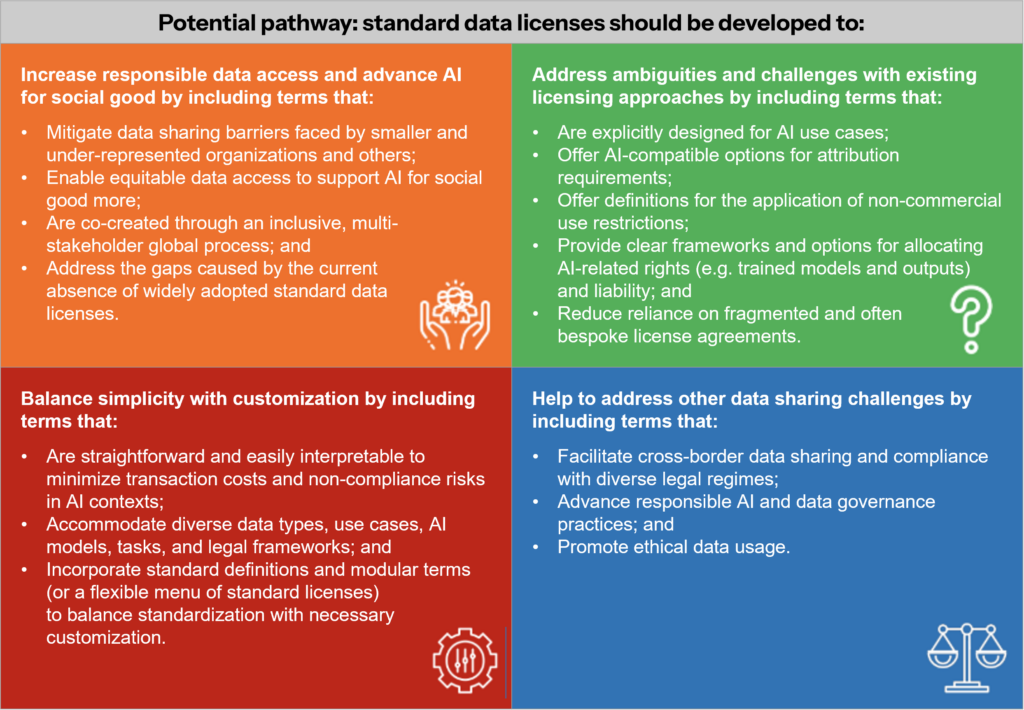
1. New standard data licenses can promote greater responsible data access and AI for social good.
a) No standardized data licenses have been widely adopted, increasing data sharing challenges for under-represented and smaller organizations. The research indicates that the lack of widely adopted, standardized data licenses may create significant barriers to voluntary, legally compliant, and ethical data sharing. This gap might drive up costs and impose contractual burdens that particularly hinder smaller or under-represented organizations from fully benefiting from AI.
b) Data access disparities also impact the advancement of AI for social good. Limited cross-cultural and cross-linguistic data sharing can restrict access to high-quality datasets. The research shows that this shortfall might not only impede responsible AI development among research institutions, governments, and non-profits (especially in developing regions) but also diminish the diversity and richness of AI models.
c) Multi-stakeholder participation can help develop standard data licenses that advance equitable data access and AI for social good. According to the research, involving a diverse range of stakeholders (including representatives from different geographic regions, sectors, and groups that have traditionally faced challenges in the technology sector) appears to be essential. Such multi-stakeholder participation can lead to the development of standard licensing frameworks that more effectively address disparities and foster equitable data access for social good.
2. New standard data licenses can help address existing ambiguities and challenges with current contractual approaches to data sharing.
a) The lack of widely embraced standard data licenses leads to inconsistency and incompatibility and increases the challenges of using data in compliance with license terms. Through this research, it was confirmed that customized license agreements currently in use may lead to inconsistencies and incompatibilities, which in turn increase legal uncertainty and compliance costs. This fragmentation overall makes it more challenging for organizations to share data effectively across their ecosystems.
b) Confusion exists about the meaning of non-commercial limitations in data licenses, and clarification in new standard licenses might encourage more data-sharing transactions. This work highlights that the lack of definitions of “non-commercial” use in current licenses creates significant confusion. Clarifying this term within standard licenses could encourage more frequent and compliant data-sharing transactions.
c) New standard data licenses could clarify rights emerging from AI and provide different options for contractually allocating rights and liabilities. The research shows that commonly used existing licenses do not clearly address the allocation of rights for data usage (or for AI models and outputs developed using such data) resulting in uncertainties regarding rights and liabilities. Standard licenses that offer clearer contractual options, in line with applicable laws, could help resolve these issues.
d) New standard data licenses can help address attribution issues arising under existing agreements. Attribution requirements in widely used license frameworks can be impractical for AI applications, where data used in model training is not directly reproduced in outputs. The research therefore suggests that standardizing license terms and integrating technical solutions like automatic attribution may reduce this ambiguity and simplify data sharing.
3. New standard data licenses should embrace simplicity while balancing standardization with the need for some customization.
a) There is a pressing need for simplicity. Throughout, the research emphasized that drafting licenses in clear, easily interpretable language is critical for reducing transaction costs and building trust, especially for non-legal practitioners.
b) Standard data licensing frameworks should balance the need for standardization with some customization, given the many data types, use cases, models, tasks, and legal requirements. The research also indicates that while standardization can streamline data sharing, licenses may also need to allow for some customization to accommodate the diversity of data types, use cases, AI models, and jurisdiction-specific legal requirements across the AI data lifecycle.
c) Standard modular data license terms (and/or a menu of standard data license agreements) could balance standardization and some customization. Therefore, the research suggests that a modular framework or a menu of license options (developed through a collaborative, multi-stakeholder process) could effectively balance the need for uniformity with the necessity for customization to address varied stakeholder needs.
d) Standard definitions can advance data licensing. The research points to the potential benefits of developing and adopting standard definitions for key terms. Such definitions can further simplify license agreements and help maintain an effective balance between standardization and necessary customization.
4. A new standard data licensing framework may help address other data-sharing challenges, including legal compliance, data and AI governance, and ethical considerations.
a) Standard data license agreements could help address other challenges in implementing voluntary, legally compliant data sharing, including by helping advance data and AI governance. Ensuring technical tools for tracking data provenance and lineage and for easily processing the terms of standard licenses can enhance transparency and reduce compliance costs. This, the research shows, can support stronger data and AI governance practices. For instance, MLCommons’ Croissant initiative (a metadata format for ML datasets) simplifies discovery and integration by embedding legal and compliance measures into the AI pipeline. This can help to reduce uncertainty in data-sharing exchanges by representing legal and contractual frameworks as metadata. Lastly, complementary tools, such as automatic attribution services in Apache Atlas, can further ensure that license-defined rights are easily represented and therefore upheld.
b) Standard data licenses may help address cross-border and other compliance challenges. The diversity of data-related regulations across jurisdictions (e.g., data protection) continues to create substantial barriers to data sharing. To ease compliance, standard data license terms should be prepared with these legal matters in mind.
c) Standard data licenses may help advance ethical guidelines for data usage. The research confirmed interest in having ethical restrictions on data and AI model usage in at least some scenarios. A new standard data licensing framework could reference relevant ethical codes of conduct. Some concern was expressed about incorporating codes of conduct or standards, which could change over time, into standard data licenses, as this could increase uncertainty in the contractual terms and costs of compliance. These factors should be considered in the global and multi-stakeholder process developed to prepare standard licenses.
Looking forward
Overall, this work shows promising signs that adopting modular, standard data license agreements can clarify key terms, reduce transaction costs, and enable more accessible data use across borders and sectors. Additionally, it demonstrates that integrating external technical tools and frameworks like Apache Atlas and Croissant with these legal frameworks enhances data discoverability and usability. Together, these measures can help to build a transparent, interoperable ecosystem for responsible AI development. Here, we have the opportunity to shape an AI-driven future that is equitable, sustainable, and indeed serves everyone.