
About MLPerf Training
The field of AI has been rapidly advancing over the past decade, and the MLPerf® Training benchmark suite is constantly evolving to capture the zeitgeist. New benchmarks are added based on MLCommons® member consensus and customer interests.
For MLPerf Training v4.0, we are pleased to introduce a graph neural network (GNN) training benchmark based on the Relational Graph Attention Network (R-GAT) model. The benchmark is a result of almost a year of close collaboration between teams from Alibaba, Intel, and NVIDIA.
About graph neural networks
Graph neural networks (GNNs) have emerged as an important class of models to employ with graph-structured data such as social graphs. GNNs are used in a wide range of areas such as recommendation systems, fraud detection, knowledge graph answering, and drug discovery, to name a few. From a computational perspective, sparse operations and message passing between nodes of the graph make GNNs stand apart from other benchmarks in the training suite and present new challenges for system optimization and scalability.
Dataset and model
Commercial applications of GNNs typically use very large graphs that do not fit into the memory of a single node. To reflect the multi-node nature of the workload, we sought to use the largest available public dataset. Our initial proposal was to use the MAG-240M dataset from Open Graph Benchmarks, consisting of ~240 million nodes and ~1.7 billion edges. With the release of the Illinois Graph Benchmark (IGB) dataset in March 2023, we settled upon using the heterogeneous version of the dataset (IGBH-Full) for the benchmark. For more details, please refer to the IGB publication and repo.
The IGBH dataset is a real-world citation graph consisting of ~547 million nodes and ~5.8 billion edges, with more than 40% labeled nodes. The dataset schema is illustrated in Figure 1. The benchmark’s task is to classify the paper nodes of the graph among 2,983 available topics. We also augment the dataset by adding reverse edges to improve accuracy.
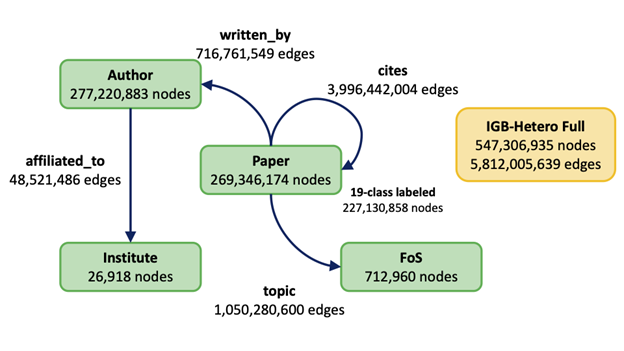
Figure 1: IGB-Heterogeneous dataset schema (source).
While there are a variety of architectures for GNNs, we chose to use the R-GAT model due to its popularity. This model leverages the attention mechanism proposed in the transformer model to focus on data subsets that are of greatest importance. After a thorough exploration of model architectures, we arrived at a configuration that achieves 72% classification accuracy on the validation set.
Technical details
We use a R-GAT model with three layers with [5,10,15] fanout, hidden dimension of 512, and four attention heads. The model is trained from scratch on a predetermined training subset of the graph (60% of the nodes) using the Adam optimizer. The eval dataset is fixed to be a 1/40th fraction of the full validation dataset–about 0.8 million nodes–with accuracy evaluated 20 times per epoch. To obtain a representative result, submitters must run the benchmark 10 times with different random seeds. Results are then scored using Olympic averaging.
The reference code is implemented using Alibaba’s GraphLearn-for-Pytorch (GLT) framework. GLT is a library for large-scale GNN training in Pytorch which supports distributed CPU/GPU-based sampling and training and is fully compatible with PyG. The reference code is designed to run on both NVIDIA GPUs and Intel Xeon platforms.
As we developed the benchmark, we had a healthy debate on the rules governing the benchmark so that the typical industry use case is reflected. For multi-node runs, the graph must be partitioned so that features of a given graph node are read exclusively from one training node to ensure feature-fetching over the network. We also spent considerable effort understanding the sampling differences between PyG and DGL, the two popular GNN frameworks. While the two samplers are not mathematically equivalent, we allow submitters to use either version out of the box because the convergence differences between them were minimal in our experiments. We have also contributed a PyG-style sampler in DGL for community usage.
We recently submitted MLPerf R-GAT to the Illinois Graph Benchmark (IGB) leaderboard which helps the industry keep track of the state of the art for GNN models, encouraging reproducibility, and we are pleased to announce that our submission is currently #1 with a 72% test accuracy.
Conclusion
We have described the motivation and the process of creating the new MLPerf GNN training benchmark. This benchmark will allow for fair evaluation of various systems, frameworks, and optimization techniques today and is expected to influence the design of future AI systems. We are delighted by the community interest in this benchmark, as shown by the number of submissions to MLPerf Training v4.0, and hope to see this interest grow further.
Further details of the benchmark and the reference implementation can be found here.