MLPerf Training Benchmark Suite Results

Overview
The MLPerf Training benchmark suite measures how fast systems can train models to a target quality metric. Current and previous results can be reviewed through the results dashboard below.
The MLPerf Training benchmark paper provides a detailed description of the motivation and guiding principles behind the MLPerf Training benchmark suite.
Results
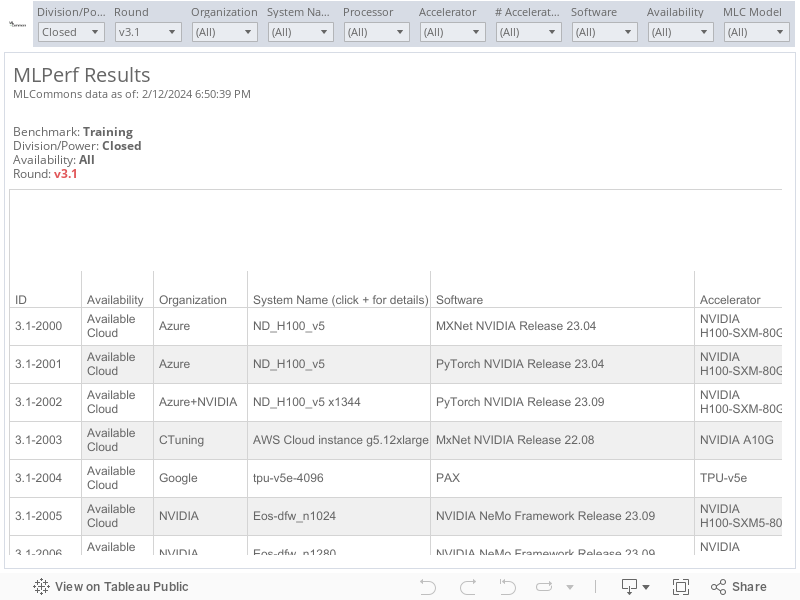
MLCommons results are shown in an interactive table to enable you to explore the results. You can apply filters to see just the information you want and click across the top tabs to view the results visually. To see all result details, expand the columns by clicking on the “+” icon, which appears when you hover over “System Name” and subsequent columns.
Benchmarks
Each benchmark is defined by a Dataset and Quality Target. The following table summarizes the benchmarks in this version of the suite. The rules remain the official source of truth.
| Area | Benchmark | Dataset | Quality Target | Reference Implementation Model |
| Vision | Image classification | ImageNet | 75.90% classification | ResNet-50 v1.5 |
| Vision | Image segmentation (medical) | KiTS19 | 0.908 Mean DICE score | 3D U-Net |
| Vision | Object detection (light weight) | Open Images | 34.0% mAP | RetinaNet |
| Vision | Object detection (heavy weight) | COCO | 0.377 Box min AP and 0.339 Mask min AP | Mask R-CNN |
| Language | Speech recognition | LibriSpeech | 0.058 Word Error Rate | RNN-T |
| Language | NLP | Wikipedia 2020/01/01 | 0.72 Mask-LM accuracy | BERT-large |
| Language | LLM | C4 | 2.69 log perplexity | GPT3 |
| Commerce | Recommendation | Criteo 4TB multi-hot | 0.8032 AUC | DLRM-dcnv2 |
| Area | Benchmark | Dataset | Quality Target | Reference Implementation Model | Latest Version Available |
|---|---|---|---|---|---|
| Vision | Image classification | ImageNet | 75.90% classification | ResNet-50 v1.5 | v3.1 |
| Vision | Image segmentation (medical) | KiTS19 | 0.908 Mean DICE score | 3D U-Net | v3.1 |
| Vision | Object detection (light weight) | Open Images | 34.0% mAP | RetinaNet | v3.1 |
| Vision | Object detection (heavy weight) | COCO | 0.377 Box min AP and 0.339 Mask min AP | Mask R-CNN | v3.1 |
| Language | Speech recognition | LibriSpeech | 0.058 Word Error Rate | RNN-T | v3.1 |
| Language | NLP | Wikipedia 2020/01/01 | 0.72 Mask-LM accuracy | BERT-large | v3.1 |
| Language | LLM | C4 | 2.69 log perplexity | GPT3 | v3.1 |
| Commerce | Recommendation | Criteo 4TB multi-hot | 0.8032 AUC | DLRM-dcnv2 | v3.1 |
| Marketing, Art, Gaming | Image Generation | LAION-400M-filtered | FID<=90 and CLIP>=0.15 | Stable Diffusionv2 | v3.1 |
| Commerce | Recommendation | 1TB Click Logs | 0.8025 AUC | DLRM | v2.1 |
| Research | Reinforcement learning | Go | 50% win rate vs. checkpoint | Mini Go (based on Alpha Go paper) | v2.1 |
| Vision | Object detection (light weight) | COCO | 23.0% mAP | SSD | v1.1 |
| Language | Translation (recurrent) | WMT English-German | 24.0 Sacre BLEU | NMT | v0.7 |
| Language | Translation (non-recurrent) | WMT English-German | 25.00 BLEU | Transformer | v0.7 |
Scenarios and Metrics
Each benchmark measures the wall clock time required to train a model on the specified dataset to achieve the specified quality target.
To account for the substantial variance in ML training times, final results are obtained by measuring the benchmark a benchmark-specific number of times, discarding the lowest and highest results, and averaging the remaining results. Even the multiple result average is not sufficient to eliminate all variance. Imaging benchmark results are very roughly +/- 2.5% and other benchmarks are very roughly +/- 5%.
For non-HPC training, results that converged in fewer epochs than the reference implementation run with the same hyperparameters were normalized to the expected number of epochs.
Divisions
MLPerf aims to encourage innovation in software as well as hardware by allowing submitters to reimplement the reference implementations. Two Divisions allow different levels of flexibility during reimplementation: The Closed division is intended to compare hardware platforms or software frameworks “apples-to-apples” and requires using the same model and optimizer as the reference implementation; the Open division is intended to foster faster models and optimizers and allows any ML approach that can reach the target quality.
Availability
MLPerf divides benchmark results into Categories based on availability. Available systems contain only components that are available for purchase or for rent in the cloud.
Preview systems must be submittable as Available in the next submission round. Research, Development, or Internal (RDI) contain experimental, in development, or internal-use hardware or software. Any Preview systems not submitting as Available in the next submission round will be noted as invalid.
Submission Information
Each row in the results table is a set of results produced by a single submitter using the same software stack and hardware platform.

Submitter
The organization that submitted the results.

Software
The ML framework and primary ML hardware library used.

System
General system description.
Benchmark Results
Results for each benchmark as described above.

Processor and Count
The type and number of CPUs used, if CPUs perform the majority of ML compute.

Details
Link to metadata for submission.

Accelerator and Count
The type and number of accelerators used, if accelerators perform the majority of ML compute.

Code
Link to code for submission.
Each Open division row may add the following information:
Model Used
The model used to produce the results, which may or may not match the Closed Division requirement.
Notes
Arbitrary notes from submitter.
Rules
The rules are here.
Reference Implementations
Reference implementations for the benchmarks are here.
Results Usage Guidelines
MLPerf™ is a trademark of MLCommons®. If you use it and refer to MLPerf results, you must follow the results guidelines. MLCommons reserves the right to determine appropriate uses of its trademark.
