MLPerf Storage Benchmark Suite Results

Overview
The MLPerf Storage benchmark suite measures how fast storage systems can supply training data when a model is being trained. Below is a short summary of the workloads and metrics from the latest round of benchmark results submissions.
Results
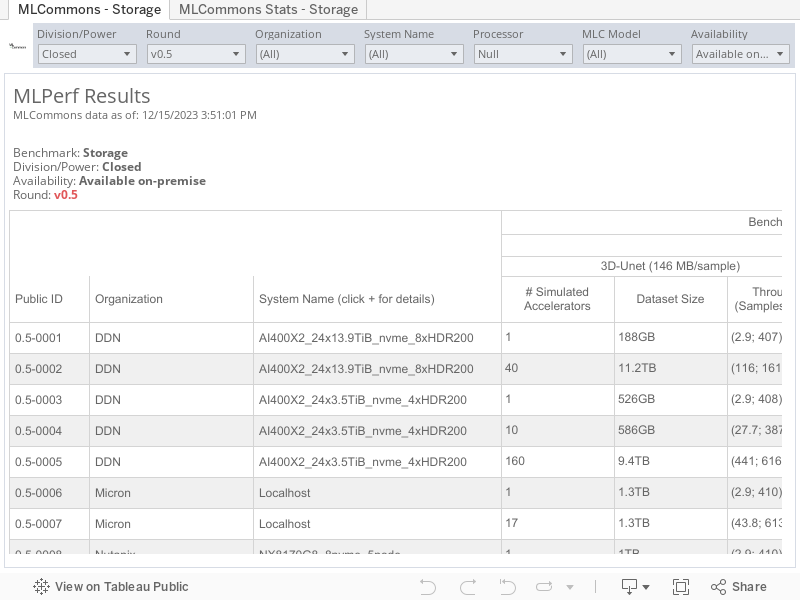
MLCommons results are shown in an interactive table to enable you to explore the results. You can apply filters to see just the information you want and click across the top tabs to view the results visually. To see all result details, expand the columns by clicking on the “+” icon, which appears when you hover over “System Name” and subsequent columns.
Workloads
Each workload supported by MLPerf Storage is defined by a corresponding MLPerf Training benchmark. The following table summarizes the workloads in this version of the benchmark (the rules remain the official source of truth):
| Area | Task | Model | Nominal Dataset (see below) | Latest Version Available |
|---|---|---|---|---|
| Vision | Medical image segmentation | 3D UNET | KITS 2019 (602x512x512) | v0.5 |
| Language | Language processing | BERT-large | Wikipedia (2.5KB/sample) | v0.5 |
The dataset is referred to as a “nominal dataset” above because the MLPerf Storage benchmark simulates the above named real datasets using synthetically generated populations of files where the distribution of the size of the files matches the distribution in the real dataset. The size of the dataset used in each benchmark submission is automatically scaled to a size that prevents significant caching of the dataset in the systems actually running the benchmark code.
Divisions
MLPerf aims to encourage innovation in the architectures of storage systems that support AI/ML projects. It has two Divisions with different purposes:
- The Closed division is intended to allow comparisons between storage systems in an “apples-to-apples” fashion and requires using a fixed set of benchmark tunables and options when running the benchmark.
- The Open division is intended to foster innovation, to show how performance could be increased if some changes were made. As a result, it allows using different data storage formats, access methods, tunables, and options.
See the rules for specifics on what can be changed in each Division.
Availability
MLPerf divides benchmark results into categories based on the availability of the storage solution:
- Available on premise – shows results for systems that are available in a customer datacenter.
- Available via the ALCF Discretionary Allocation Program – shows results for systems that are available in the Argonne National Laboratory Discretionary Allocation Program.
- Research, Development, or Internal (RDI) – contains experimental, in development, or internal-use hardware or software.
Submission Information
Each row in the results table is a set of results produced by a single submitter that all use the same software stack and hardware platform in a single deployment method. Each row in the Closed and the Open division tables contains the following information:

Submitter
The name of the organization that submitted the results.

Storage Protocol & Software
The technique the compute node(s) used to access the storage system (eg: which standard protocol or proprietary software) and the name and version of the software running the storage system.

System Name
A general description or name of the system under test.
Hardware
A rough overview of the hardware used by the storage solution – at a minimum, the number of “storage controllers” and the type or technology of storage drives used by the solution.

System Type
One of several categories that characterize the architecture, eg: local storage, parallel filesystem, software defined storage, etc.

Networking
A rough overview of the networking used by the storage solution to connect the compute node(s) to the storage system – at a minimum, the type and speed of the links.

Total Usable Capacity
The amount of user data the solution can store.

Number of Compute Nodes
The number of compute nodes that ran the benchmark and accessed the storage.
Simulated Accelerator Type
The vendor and model number of accelerator that the benchmark was simulating during this test.
Each row in the results table contains the following information for each workload submitted:
Throughput
This is the maximum performance the storage system was able to deliver while maintaining all the accelerator(s) at 90% utilization or above (ie: no more than 10% of the time were the accelerator(s) idle and waiting for the storage system to deliver data). It is reported as both “samples/second”, a metric that should be intuitively valuable to AI/ML practitioners, and as “MB/s”, a metric that should be intuitively valuable to storage practitioners.
Number of Simulated Accelerators
The number of simulated accelerators active during this test; ie: how many accelerators of the given type can this storage system keep busy.
Dataset Size
Since the dataset used in this test was synthesized and must be of a size to prevent significant caching of data in the compute node(s) running the benchmark, the size of the dataset used in this test is reported here.
Rules
MLPerf Storage rules for the current submissions round are available here.
Reference implementations
Source code for the benchmark is available.
Results Usage Guidelines
MLPerf™ is a trademark of MLCommons®. If you use it and refer to MLPerf results, you must follow the results guidelines. MLCommons reserves the right to determine appropriate uses of its trademark.
