As Machine Learning (ML) has grown rapidly and become more powerful, new challenges have arisen. The latest are limitations in the availability and utility of training and testing datasets for ML models. We propose DataPerf, the first platform and community to develop competitions and leaderboards for data and data-centric AI algorithms. Competitions and leaderboards have traditionally been focused on improving ML models and have inspired decades of innovation, including accomplishments such as AlexNet, the first model to surpass human performance on image recognition on the ImageNet dataset, which catalyzed the latest revolution in machine learning. By applying these proven approaches in a data-centric fashion, we believe that we can break through these dataset limitations and encourage better machine learning in the decades to come.
Data is the new bottleneck for ML
Could the keys to diagnosing and treating cancer earlier, engineering safe self-driving cars, automating fact-checking, detecting fraud, and reducing litigation costs have something in common? Machine learning (ML) promises new and exciting solutions to these problems, provided that appropriate training and testing data is available.
However, training and testing datasets are often too small, too specialized, too limited or of poor quality, and too static, leading to what we call the data bottleneck. The lack of appropriate training and testing data hinders ML development and deployment in various domains, including healthcare, transportation, finance, cybersecurity, and more.
In this blogpost, we identify the current data bottlenecks we are facing, and explain how DataPerf provides incentive for research and engineering communities to overcome these bottlenecks.
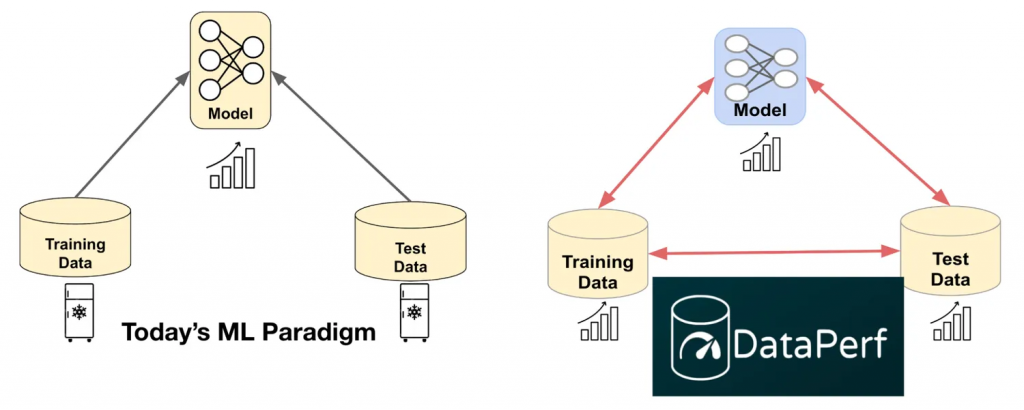
Figure 1: Changing the ML paradigm: On the left, standard ML assumes static training and test datasets. On the right, DataPerf evolves training and test data alongside models, overcoming data bottlenecks.
The first bottleneck is around data quality. Datasets for ML have a wide range of sources. For example, most ML research relies on public training and test datasets which are built from easily available data sources such as web scrapes, forums, Wikipedia, as well as crowdsourcing. However, these sources often suffer from quality, distribution, and bias, among other issues. For example, as Dollar Street has illustrated, most visual data comes from the wealthy portions of the developed world, leading to bias.
These data quality bottlenecks in turn lead to data quantity bottlenecks. The growth in data means that a large portion of the data is low-quality, which has incrementally less benefit and consequently leads to non-linear and rapid growth in model size[1]. This ultimately drives up the size and computational cost of models, leading to recent innovations requiring staggering and costly infrastructure[2]. As we exhaust our public data sources ML models may even saturate in terms of accuracy, stalling progress[3]. Last, there is a growing gap between performance on these public research data sets and the real-world. Therefore, it is crucial for the AI community to actively benchmark and conduct research to enhance the quality of training and test data. This is the core principle of the data-centric AI community.
DataPerf, the leaderboard for data
DataPerf is inspired by the success of ML Leaderboards. Leaderboards such as SQuAD, SuperGLUE, Kaggle and others have played a significant role in advancing research in ML models. These leaderboards create a shared metric for measuring progress and act as a compass for shaping ML research.
DataPerf is the first platform and community to develop leaderboards for data and data-centric AI algorithms. We aim to have a similar impact on data-centric AI research as ML leaderboards had on ML model research. DataPerf leverages Dynabench, a platform that supports benchmarking of data, data-centric algorithms, and models.
DataPerf v0.5 features five challenges that focus on five common data-centric tasks across four different application domains:
- Training data selection (Vision) – Design a data selection strategy that selects the best training set from a large candidate pool of weakly labeled training images.
- Training data selection (Speech) – Design a data selection strategy that selects the best training set from a large candidate pool of automatically extracted clips of spoken words.
- Training data Cleaning (Vision)– Design a data cleaning strategy that chooses samples to relabel from a noisy training set. The current version of this challenge targets image classification.
- Training dataset valuation (NLP) – Design a data acquisition strategy that selects the best training set from multiple data-sellers based on limited information exchanged between buyers and sellers.
- Adversarial Nibbler (Multimodal text-to-image) – Design safe-looking prompts that lead to unsafe image generations.
These challenges aim to benchmark and improve the performance of data-centric algorithms and models. Each challenge on the DataPerf website includes design documents that outline the problem, model, quality target, rules and submission guidelines. The Dynabench platform enables us to offer a live leaderboard, an online evaluation framework, and track submissions over time.
How to get involved?
As a community of machine learning researchers, data scientists, and engineers, we are committed to improving machine learning by enhancing data quality. DataPerf is calling on innovators in academia and industry to measure and validate data-centric algorithms and techniques, and to enhance datasets through these benchmarks. The first round of Dataperf 2023 challenges are open for participation on March 30th, 2023. The submission will close on May 26th, 2023. The winners of the challenge will be invited to present their work at ICML 2023, and publish their work in the forthcoming Data for ML Research (DMLR) journal.
To help, please share this blog post with your colleagues. Visit the DataPerf website to participate in the DataPerf challenges, or to design a new data-centric challenge. Join the DataPerf working group to stay up-to-date on the ongoing changes in the data-centric ML community.
We would like to thank the Dynabench engineering team for providing the infrastructure and support for DataPerf. The DataPerf benchmarks were created over the last year by engineers and scientists from: Coactive.ai, ETH Zurich, Google, Harvard University, Meta, MLCommons, and Stanford University. In addition, this effort would not have been possible without the support of DataPerf working group members from Carnegie Mellon University, Digital Prism Advisors, Hugging Face, Institute for Human and Machine Cognition, Landing.ai, San Diego Supercomputing Center, Thomson Reuters Lab, and TU Eindhoven.
References
- Hestness, Joel, et al. “Deep learning scaling is predictable, empirically.” arXiv preprint arXiv:1712.00409 (2017).
- Sevilla, Jaime, et al. “Compute trends across three eras of machine learning.” 2022 International Joint Conference on Neural Networks (IJCNN). IEEE, 2022.
- Villalobos, Pablo, et al. “Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning.” arXiv preprint arXiv:2211.04325 (2022).