
Intro
MLPerf® Inference v5.0 introduced a new automotive benchmark. From the many potential workloads related to autonomous driving, the automotive benchmark task force chose 3D object detection as the benchmark task. Based on input from experts in the autonomous driving space, the task force selected PointPainting as the benchmark model. PointPainting is a sensor-fusion technique proposed by Vora et al. in 2019 that works in conjunction with image-based semantic segmentation to classify points generated by a lidar system. The experts indicated that 3D object detection is the most useful compute-intensive task to benchmark. We selected PointPainting because it is reasonably accurate, fast for inference, and has representative components of classical and newer 3D detection models.
Model selection
Compared to other machine learning applications, progress in autonomous driving is relatively more cautious. New models must go through extended review to ensure safety and reliability. We wanted to choose a model that contains useful components from both more proven older models as well as newer state-of-the-art models used in ongoing research. We also wanted to pick a model that is representative of multiple sensor modalities while still favoring the most common case of using video/images for vision, and a sensor suite synergistic between lower-resolution, affordable lidar and higher-resolution cameras.
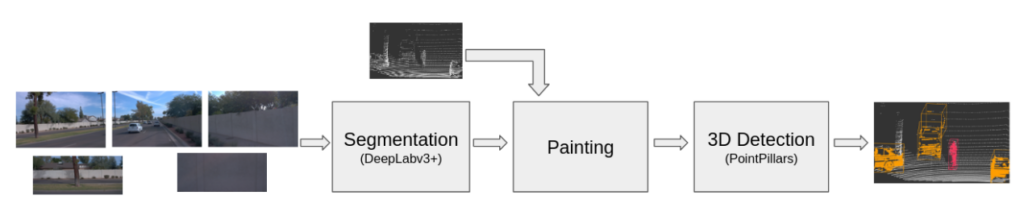
PointPainting is composed of two models: an image segmentation model that is used to “paint” lidar points by concatenating segmentation scores to lidar points and a lidar object detection model that takes the painted points as inputs and produces 3D detection predictions. A high level diagram is shown in Figure 1. We chose DeepLabv3+ with a ResNet-50 backbone as the segmentation model and PointPillars as the lidar detector. Both are popular for their respective tasks and are fast enough for real time applications. Additionally, these model choices account for about 90% of the PointPainting workload being performed in the segmentation task. Favoring images in the workload helps make the model more representative of the most common case of vision tasks while still incorporating lidar components in our model.
Dataset and task selection
Autonomous vehicles must perform many computational tasks. Our goal was to pick a task that is computationally intensive and representative of the self-driving tasks. To select one task to benchmark, we consulted with experts in the autonomous driving field. We had unanimous agreement that 3D object detection would be the most representative task. 3D tasks are inherently more computationally expensive than 2D tasks and often incorporate 2D models within them. 3D detection is also an important component of other tasks such as trajectory prediction.
We chose the Waymo Open Dataset (WOD) because it is a large high-quality dataset. Importantly, we verified that MLPerf benchmarking is considered a non-commercial use under the terms of the WOD license. The WOD provides five camera images and one lidar point cloud per frame. The images have resolutions of 1920×1280 and 1920×886 pixels. The data was captured in San Francisco, Mountain View, and Phoenix. The WOD provides annotations for 3D bounding boxes as well as video panoptic segmentation which is needed for the segmentation network.
There is no public implementation of PointPainting based on WOD. We trained a model ourselves to determine an accuracy target and generate a reference checkpoint for the benchmark. We built on the open source work of PointPillars, DeepLabv3+, PointPainting, and mmdetection 3d to create our implementation of PointPainting. As a baseline we trained PointPillars on WOD. Our goal was not to produce the most accurate version of PointPillars but to get a model with an accuracy that is representative of what can be achieved on the WOD dataset. Our PointPillars baseline achieved a mean average precision (mAP) of 49.91 across three classes (Pedestrians, Cyclists, and Vehicles).
Our trained PointPainting model is available to MLCommons® members by request here.
Performance metrics
MLPerf Inference’s single stream scenario for edge systems represents a task that accepts a single input and measures the latency for producing the output. This scenario is the closest and most relevant for an automotive workload where frames are received at a fixed rate from sensors. We chose a 99.9% accuracy threshold, as automotive workloads are safety-critical. The 99.9% latency percentile measures the 99.9% largest latency for a submission out of the required thousands of inference samples. These requirements balance the need for strong latency constraints with the desire to ensure the benchmark runtime is on the order of one day rather than weeks.
Conclusion
The automotive benchmark taskforce followed a rigorous process for choosing and building an automotive workload for MLPerf Inference. We have undertaken careful decisions regarding the task, dataset, and model to ensure the creation of a robust and representative benchmark. Additionally, we have determined accuracy targets and performance metrics that fit within MLPerf Inference while being useful for automotive tasks. MLCommons plans to continue developing automotive benchmarks across a suite of automotive-specific tasks. We welcome feedback from the community regarding this benchmark and future developments.
Additional technical contributors: Pablo Gonzalez, MLCommons; Anandhu Sooraj, MLCommons; Arjun Suresh, AMD (formerly at MLCommons).