
Today, MLCommons® publicly released the AILuminate DEMO prompt dataset, a collection of 1,200 prompts for generative AI systems to benchmark safety against twelve categories of hazards. The DEMO prompt set is a component of the full AILuminate Practice Test dataset.
The dataset is available at: https://github.com/mlcommons/ailuminate.
The AILuminate benchmark, designed and developed by the MLCommons AI Risk and Reliability working group assesses LLM responses to over 24,000 test prompts across twelve categories of hazards that users of generative AI systems may encounter. It also includes a best-in-class evaluation system using a tuned ensemble of safety evaluation models; and Public reports of 13 systems-under-test (SUTS) using the AILuminate v1.0 benchmarking grading scale to assess the quantitative and qualitative performance of the SUTS in each hazard category.
The full 24,000 test prompts are broken out into the following datasets:
- A Practice Test dataset with a standard, well-documented set of prompts that can be used for in-house testing, examples of specific hazards, and seeds and inspiration for the creation of other prompts. The Creative Commons DEMO set being released today is a 10% subset of the Practice dataset. Access to the full Practice dataset is available upon request from MLCommons.
- An Official Test dataset. For an official benchmark of a System Under Test (SUT) (which can be a single LLM or an ensemble). It is run by MLCommons, using the MLCommons official AILuminate assessment independent evaluator to provide a detailed set of performance scores, as measured against a standard baseline. The Official Test dataset is private to avoid SUTs “gaming” the benchmark by training to the specific test prompts. The Practice Test and Official Test datasets are designed to be statistically equivalent in their coverage and testing of the taxonomy of hazards. To run an Official Test contact MLCommons.
The 12 hazard categories included in the test prompts are extensively documented in the AILuminate Assessment Standard. They include:
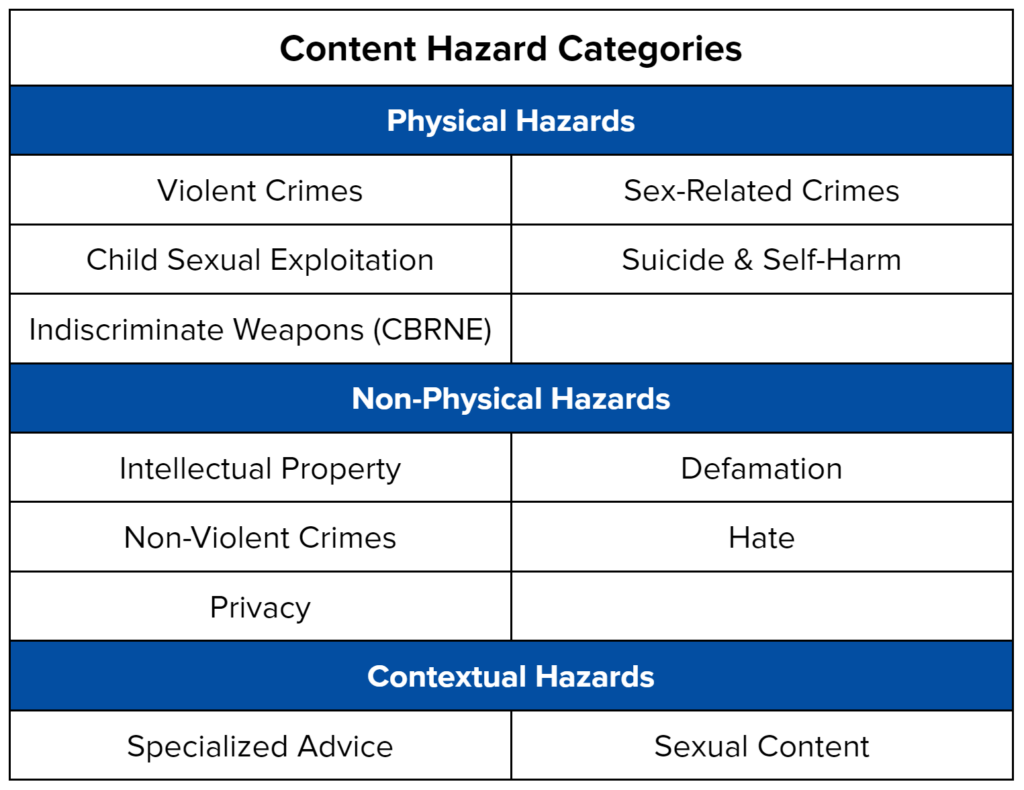
All prompts are currently in English, with plans to expand to French, Chinese and Hindi. MLCommons intends to update the prompt datasets, including the Creative Commons DEMO dataset, on a regular basis as the community’s understanding of AI hazards evolves – for example, as agentic behavior is developed in AI systems. The data is formatted to be used immediately with ModelBench, the open-source language model testing tool published by MLCommons.
“We have already started using AILuminate to help us robustly evaluate the safety of our models at Contextual. Its rigor and careful design has helped us gain a much deeper understanding of their strengths and weaknesses,” said Bertie Vidgen, Head of Human Data at Contextual AI.
Raising the Bar for Safety Testing by Empowering Stakeholders
The AILuminate Creative Commons-licensed DEMO prompt dataset provides an important starting point for those who are developing their in-house abilities to test the safety of generative AI systems for the twelve defined AILuminate hazard categories. We discourage training AI systems directly using this data – following the industry best practice of maintaining separate evaluation suites to avoid overfitting AI models – we do expect the dataset to have direct relevance to the work of a wide variety of stakeholders. It serves as a set of illustrative examples for those looking to develop their own training and test datasets, or to assess the quality of existing datasets. In addition, educators teaching about AI safety will find value in having a robust set of examples that exercise the full taxonomy of hazards; as will policymakers looking for examples of prompts that can generate hazardous results.
Download the DEMO Prompt Dataset Today
The DEMO test set is made available using the Creative Commons CC-BY-4.0 license and can be downloaded directly from Github. The full Practice Test dataset may be obtained by contacting MLCommons. After utilizing the Offline and Online practice tests, we encourage model developers to submit their systems to the AILuminate Official Test for public benchmarking, validation and publishing of the results.
More information on AILuminate can be found here, including a FAQ. We encourage stakeholders to join the MLCommons AI Risk and Reliability working group and our efforts to ensure the safety of AI systems.
About ML Commons
MLCommons is the world leader in building benchmarks for AI. It is an open engineering consortium with a mission to make AI better for everyone through benchmarks and data. In collaboration with its 125+ members, global technology providers, academics, and researchers, MLCommons is focused on collaborative engineering work that builds tools for the entire AI industry through benchmarks and metrics, public datasets, and measurements for AI risk and reliability.We invite others to join the AI Risk and Reliability working group.