Introducing PRISM
Human feedback learning for aligning large language models (LLMs) is a field that is rapidly growing in importance and influence for AI design and development. Typically, human feedback is collected as binary preference votes or numeric scores over two or more model outputs to a user prompt. To date, there’s been limited data-centric efforts to source a higher quality and quantity of human feedback from a wider spectrum of people.
Recently, researchers at the University of Oxford in collaboration with MLCommons and others, released the PRISM alignment project – a new resource for the AI community to understand how humans from around the world perceive and interact with LLMs.
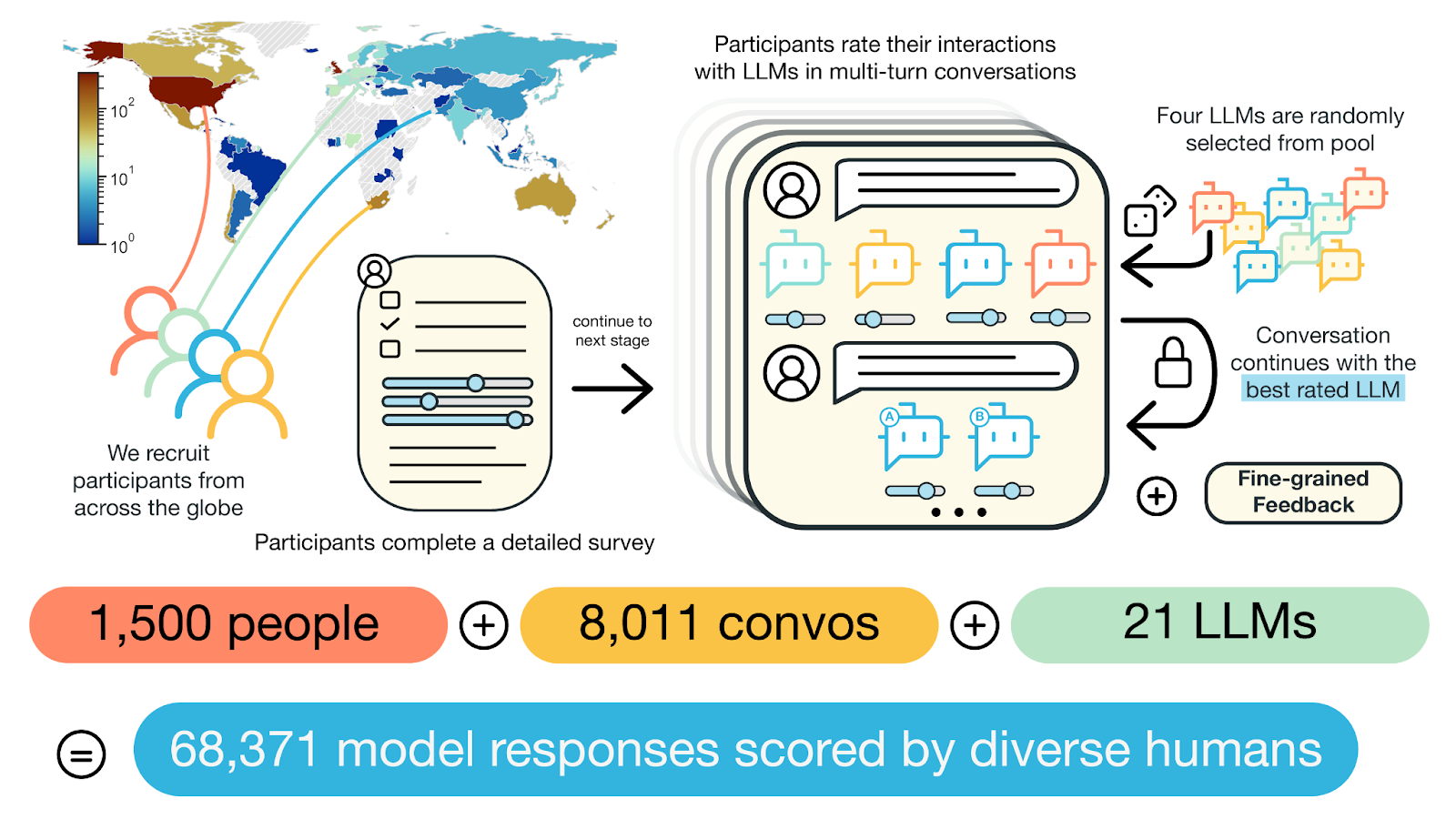
PRISM aims to diversify the voices currently contributing to the human feedback used to train LLMs. To achieve this aim, researchers collected preferences from 1,500 humans across 38 countries, as they interacted with 21 different LLMs, in real-time conversations. These conversations were hosted on Dynabench – an MLCommons® platform designed for dynamic human-and-model-in-the-loop data collection. In total, the researchers observed 8,011 conversations, amassing over 68,000 human-AI interactions. Each interaction was assigned a numeric preference intensity score, and associated with additional fine-grained feedback such as factuality, fluency, and creativity ratings as well as open-ended text feedback .
Hannah Rose Kirk, PRISM project lead, said “Human feedback learning can no longer operate under simplifying assumptions of a “generic human”. Alignment is complex precisely because it is influenced by messy human factors, interpersonal subjectivities and cross-cultural disagreements. With PRISM, we wanted to lean into these data-centric human factors and ultimately encourage more inclusive and adaptive technologies.”
Max Bartolo, co-chair of the MLCommons Data-Centric ML working group, says “Data is central to training and evaluating machine learning systems. Human preference is intricate and multifaceted, but current methods simplify this complexity. PRISM is a pioneering large-scale initiative that offers profound insights and poses critical questions, shedding light on the complex nature of human preferences and the perspectives they represent.”
Features of the PRISM Alignment Dataset
PRISM has many rich features that enable future data-centric work to be incorporated into human preferences for LLMs. For example, every rating of an LLM output on the Dynabench platform is linked back to a detailed participant survey via a pseudo-anonymised identifier. This data could be used to tailor the behaviors of LLMs to personalized preferences.
Attaching ratings to sociodemographics is valuable when considering how to aggregate preferences across groups of individuals, for example, across members of a religion, nation or continent. To understand these aggregation decisions, PRISM includes two census representative samples for the UK and the US. For the additional 30+ country-specific samples, the researchers sourced significant demographic diversity, for example by age, religious affiliation and ethnicity – especially compared to previous publicly-available human feedback datasets.
As Dr Scott A Hale, Associate Professor at the University of Oxford, and co-principal investigator on the PRISM project, explains “Having more people at the table, having more perspectives represented, ultimately leads to better technology, and it leads to technology that will raise everyone up.”
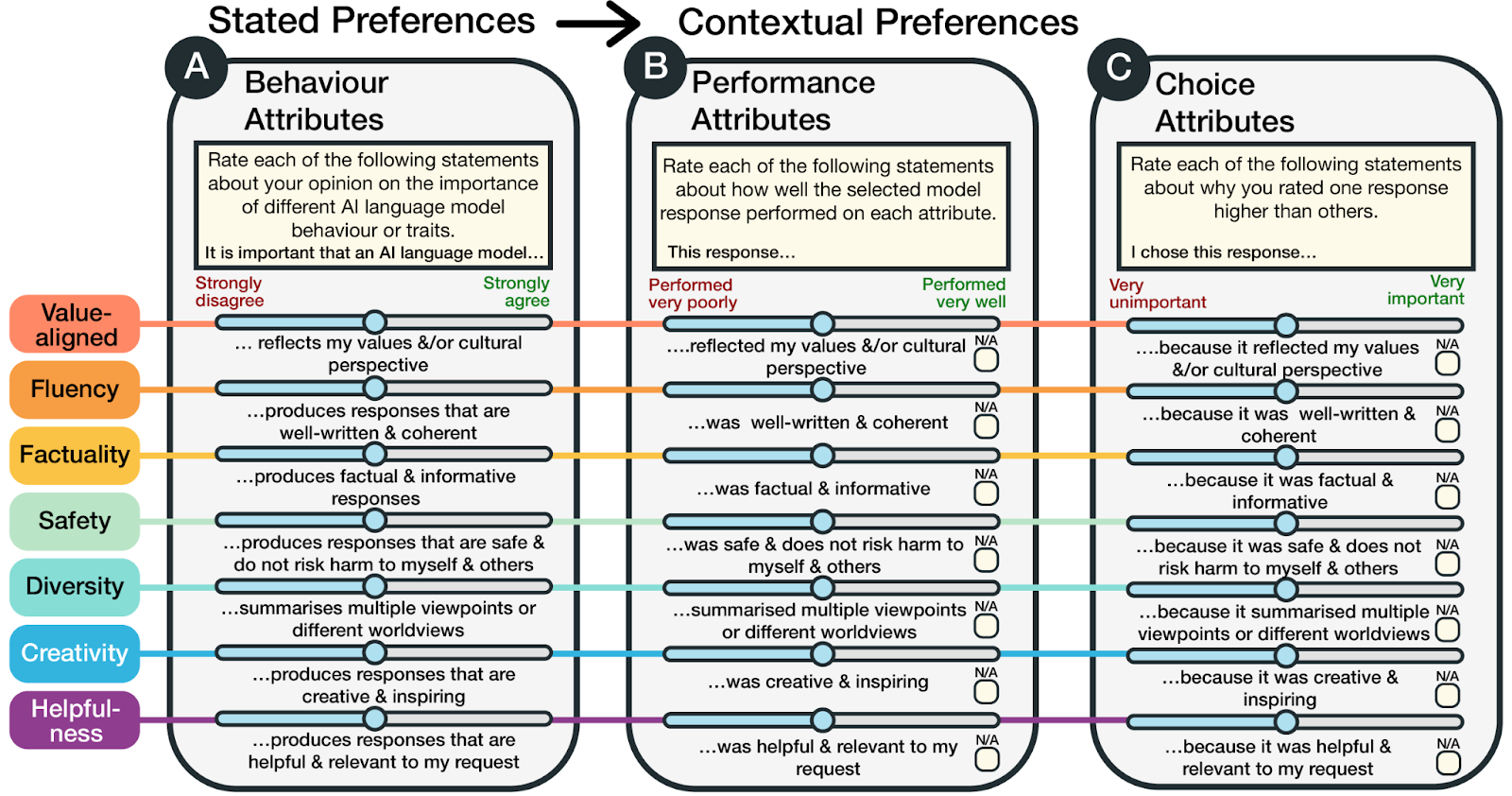
PRISM has another interesting feature compared to previous human feedback datasets: it is designed to map the stated preferences to contextual preferences. Stated preferences of participants are collected in the survey, where people are asked how important it is to them that LLMs possess general behaviors like factuality, honesty or creativity. Contextual preferences are collected for every conversation with an LLM-in-the-loop, where participants are asked how well models performed in the specific interaction, and how important these performance factors were in determining why one model was scored higher than another. Comparing these two types of preferences allows researchers to understand how different conversations cause departures from global priorities or principles of AI behaviors.
How MLCommons Solved Engineering Challenges to Facilitate Live Interactions with Multiple LLMs
The success of PRISM relied heavily on building an interface for participants to dynamically interact with LLMs, in naturalistic, low latency settings, and a clean UX design. PRISM is the first MLCommons project to build capabilities for LLM data collection and research. The updates to the MLCommons Dynabench Platform included plugins of LLMs in the backend, new rating scales, and a sleek chat interface. These are now being used for future research projects, such as HELP-MED, another University of Oxford led project where users interact with LLMs to assist in the discovery of medical knowledge.
Juan Ciro, MLCommons Engineer and PRISM project author says, “dealing with so many users concurrently meant rebuilding some of the Dynabench platform’s base elements and, although very challenging, seeing the platform evolve was truly gratifying”. Rafael Mosquera, MLCommons Engineer and author, says, “from an engineering standpoint, PRISM allowed us to understand the complexities behind serving LLMs. From a research perspective, we also got a sense of the difficulties that arise when evaluating the performance of these models on standard benchmarks. It was very surprising to see PRISM participants on average rating models like GPT-4 less favorably than smaller models, like Zephyr-7B. We hope the dataset allows other researchers to rethink what alignment means, and perhaps think about different demographics when training and evaluating LLMs.”
Beyond the Dataset: Should all domains be treated equally when crowdsourcing human preference data?
High-quality open-access human feedback is a scarce resource in the AI community. So, it may not be wise to treat all domains as equally in need. The PRISM project authors say that diverse perspectives on LLM behaviors are not needed equally everywhere: the prompt “what is the capital of France?” can be treated differently to “is abortion morally right or wrong?” PRISM targets its efforts in areas of high interpersonal and cross-cultural disagreement, where the majority of conversations center on values-guided topics (e.g., religion, politics, family) or controversial issues (e.g., gun rights, abortion, global conflicts or euthanasia). However, there are challenges in crowdsourcing perspectives to controversial issues, especially in choosing which people to sample and how to weigh their opinions, how to balance competing or conflicting interests, and ensure safe responses to harmful prompts.
As co-principal investigator on the project, and MLCommons AI Safety Working Group lead, Bertie Vidgen says “PRISM shows that you shouldn’t ask ‘Is your model aligned’ but instead ‘Who has it been aligned to?’ and ‘How has it been aligned?’ This exciting work has huge implications for how we think about the values, safety, and design of models.“
Use the Dataset
In line with MLCommons mission to develop rich datasets for the community of researchers and developers, PRISM offers many avenues of future research and is fully open-access.
The dataset can be downloaded at: https://doi.org/10.57967/hf/2113.
A preprint describing the dataset and findings is also available at: [2404.16019] The PRISM Alignment Project: What Participatory, Representative and Individualised Human Feedback Reveals About the Subjective and Multicultural Alignment of Large Language Models
PRISM was supported by a variety of funders, including MetaAI’s Dynabench Grants for optimizing human-and-model-in-the-loop feedback and Microsoft’s Advancing Foundation Models Research (AFMR) grant program. It also received support in the form of credit or research access from OpenAI, Hugging Face, Anthropic, Google, Aleph Alpha and Cohere.
A full acknowledgement and disclosure of the funding statement can be found in the paper.